Как сохранить в файл вывод консоли (терминала) в Linux. Linux: Запись результаты команды терминала в файл Linux вывод команды в файл
Системное администрирование Linux-систем, да и вообще администрирование любой UNIX-подобной системы. Неразрывно связано с работой в командных оболочках. Для опытных системных администраторов такой способ взаимодействия с системой является гораздо более удобным и быстрым, нежели использование графических оболочек и интерфейсов. Конечно, это многим сразу покажется преувеличением, но это неоспоримый факт. Постоянно подтверждаемый на практике. А возможна такая ситуация благодаря некоторым хитростям и инструментам, используемых при работе с командной консолью. И одним из таких инструментов является использование информационных каналов и перенаправления потоков данных для процессов.
Немного теории
Следует начать с того, что для каждого процесса система предоставляет в «пользование» как минимум три информационных канала:
- STDIN – стандартный ввод;
- STDOUT – стандартный вывод;
- STDERR – стандартная ошибка.
Строгой принадлежности этих каналов для каждого процесса нет. Сами процессы изначально появившись в системе «не знают» о том, кому и как принадлежат каналы. Они (каналы) являются общесистемным ресурсом. Хотя и устанавливаются ядром от имени процесса. Каналы могут связывать файлы, каналы, связывающие другие процессы, подключения к сети и т. д.
В UNIX-подобных системах, согласно модели ввода-вывода. Каждому из информационных каналов присваивается целочисленное значение в качестве номера. Однако для безопасного доступа. к вышеприведённым каналам. За ними зарезервированы постоянные номера - 0, 1 и 2 для STDIN, STDOUT и STDERR соответственно. Во время выполнения процессов считывание входных данных происходит по STDIN. Через клавиатуру, с вывода другого процесса, файла и т. д.. А выходные данные (через STDOUT), а также данные об ошибках (через STDERR). Выводятся на экран, в файл, на вход (уже через STDIN другого процесса) в другую программу.
Для изменения направления информационных каналов и связи их с файлами существуют специальные инструкции в виде символов <, > и >>. Так, например инструкцией < можно заставить направить процессу по STDIN содержимое файла. А с помощью инструкции > процесс по STDOUT передаёт выходные данные в файл, при этом заменяется всё содержимое существующего файла целиком. При отсутствии он будет создан. Инструкция >> выполняет то же самое, что и >, но не перезаписывает файл, а дописывает вывод в его конец. Для объединения потоков (т. е. для направления их в один и тот же приёмник) STDOUT и STDERR нужно использовать конструкцию >&. Для направления одного из потоков, например STDERR в отдельное место существует инструкция 2>.
Для связывания между собой двух каналов. Например когда нужно вывод одной команды направить на вход другой. Следует использовать для этого инструкцию (символ) «|». Который означает логическую операцию «или». Однако в контексте связывания потоков данная интерпретация не имеет значения, что нередко сбивает с толку новичков. Благодаря таким возможностям можно составлять целые командные конвейеры. Что делает работу в командных оболочках очень эффективной.
Вывод в файл
Направление вывода команды и запись этого вывода в файл /tmp/somemessage:
$ echo “This is a test message” > /tmp/somemessage
В данном случае в качестве команды с выхода которой (по STDOUT) перенаправляются данные в виде текста «This is a test massage » является утилита echo. В результате создасться файл /tmp/somemessage, в котором будет запись «This is a test message». Если файл не был создан то он создасться, если создан, то все данные в нем перезапишутся. Если нужно дописать вывод в конец файла, нужно использовать оператор «>>»
$ echo “This is a test message” >> /tmp/somemessage $ cat /tmp/somemessage This is a test message This is a test message
Как видим из примера вторая команда дописала строчку в конец файла.
Получение данных из файла
Следующий пример демонстрирует перенаправление входа:
$ mail -s "Mail test" john < /tmp/somemessage
В правой части команды (после символа <) находится файл-источник /tmp/somemesage, содержимое которого перенаправляется в утилиту mail (через STDIN), которая в свою очередь, имеет в качестве собственных параметров заголовок письма и адресата (john).
Другие примеры
Следующий пример показывает, почему иногда очень полезно разделять потоки из каналов STDIN и STDERR:
$ find / -name core 2> /dev/null
Дело в том, что команда find / -name core будет «сыпать» сообщениями об ошибках, направляя их по-умолчанию в то же место, что и результаты поиска. Т. е. в терминал командной консоли, что существенно затруднит восприятие информации пользователем. Т. к. искомые результаты затеряются среди многочисленных сообщений об ошибках, связанных с режимом доступа. Конструкция 2>/dev/null заставляет утилиту find отправлять сообщения об ошибках (следующие по каналу STDERR с зарезервированным номером 2) на фиктивное устройство /dev/null, оставляя в выводе только результаты поиска.
$ find / -name core > /tmp/corefiles 2> /dev/null
Здесь конструкция > /tmp/corefiles перенаправляет вывод утилиты find (по каналу STDOUT) в файл /tmp/corefiles. Сообщения об ошибках отсеиваются на /dev/null, не попадая в вывод терминала командной консоли.
Для связывания между собой разных каналов для разных команд:
$ fsck --help | drep M
M не проверять примонтированные файловые системы
Эта команда выведет строку (или строки), содержащие символ «M» из страницы быстрой справки к утилите . Это очень удобно, когда нужно посмотреть только интересующую информацию. В данном случае утилита grep получает вывод (по инструкции |) от команды fsck —help. И далее по шаблону «M» отбрасывает всё лишнее.
Если нужно, чтобы следующая в конвейере команда выполнялась только после полного и успешного завершения предыдущей команды, то для этого следует использовать инструкцию &&, например:
$ lpr /tmp/t2 && rm /tmp/page1
Эта команда удалит файл /tmp/page1 только тогда, когда содержимое из него будет отправлено из очереди на печать. Для достижения обратного эффекта, т. е. когда нужно выполнение следующей команды в конвейере только после того, как предыдущая не выполнится (завершится с ошибкой с ненулевым кодом), то следует использовать конструкцию ||.
Когда строка кода, включающая слишком длинный конвейер команд тяжело воспринимается, можно разбивать её на логические компоненты по строкам с помощью символа обратной черты «\»:
$ ср --preserve --recursive /etc/* /spare/backup \ || echo "Make backup error"
Отдельные команды, которые должны выполняться друг за другом можно объединять в одну строку, разделяя их символом двоеточия «;»:
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter .
Система ввода/вывода в LINUX .
В системе ввода/вывода все внешние устройства рассматриваются как файлы, над которыми допускается производить обычные файловые операции. Конечно, существуют и драйверы устройств, но интерфейс с ними оформлен для пользователя как обращение к специальному файлу. Специальные файлы являются средством унификации системы ввода/вывода.
Каждому
подключенному устройству (терминалу, дискам, принтеру и т. д.), соответствует,
как минимум, один специальный файл. Большая часть этих специальных файлов
хранится в каталоге /dev:
$ cd /dev
$ ls -l
onsole
пульт управления системы
dsk
порции на диске
fd0
флоппи-диск 1
mem память
lр принтер
lр0
параллельный порт 0
. . .
root
порция на диске для корневой файловой системы
swap
своп-порция
syscon
альтернативное имя пульта
systty
еще одно имя для системной консоли
term
директория для терминалов
ttyS0
серийный порт 0 (COM1)
. . .
Когда программа выполняет запись в такой специальный файл, то ОС система перехватывает их и направляет на устройство, например принтер). При чтении данных из такого типа файла в действительности они принимаются с устройства, например, с диска. Программа не должна учитывать особенности работы устройства ввода/вывода. Для этой цели и служат специальные файлы (драйверы), которые выполняют функции интерфейса между компонентами ядра ОС и прикладными программами общего назначения.
Система
обнаруживает отличие обычного файла от специального только после того, как
будет проанализирован соответствующий индексный дескриптор, на который
ссылается запись в каталоге.
Индексный
дескриптор специального файла содержит информацию о классе устройства, его типе
и номере. Класс устройства определяет устройства с посимвольным обменом и с
поблочным обменом. Примером устройства с посимвольным обменом может служить
клавиатура. Специальные файлы, обеспечивающие связь с устройствами такого типа,
называют байт-ориентированными. Для блочных устройств характерен обмен большими
блоками информации, это ускоряет обмен и делает его более эффективным. Все
дисковые устройства поддерживают блочный обмен, а специальные файлы,
обслуживающие их, называют блок-ориентированными. Специальные файлы не содержат
какой-либо символьной информации, поэтому в листинге каталога их длина не
указывается.
Тип и номер устройства, также являются основными характеристиками специальных файлов (в поле длины помещаются главный и дополнительный номера соответствующего устройства). Первый из них определяет тип устройства, второй - идентифицирует его среди однотипных устройств. ОС может одновременно обслуживать несколько десятков, и даже сотни терминалов. Каждый из них должен иметь свой собственный специальный файл, поэтому наличие главного и дополнительного номеров позволяет установить требуемое соответствие между устройством и таким файлом.
На одном диске можно создать несколько файловых систем. Некоторые системы используют по одной файловой системе на диске, а другие - по несколько. Новую файловую систему можно создать с помощью команды mkfs (make file system). Например, выражение # /sbin/mkfs /dev/dsk/fl1 512 означает: создать на флоппи-диске b: размером в 512 блоков.
По желанию можно задать размер файловой системы в блоках и количество i-узлов (т. е. максимальное число файлов, которые могут быть сохранены в файловой системе). По умолчанию число i-узлов равно числу блоков, деленному на четыре. Максимальное число i-узлов в одной файловой системе 65 000. Если по некоторым причинам вам необходимо более 65000 i-узлов на диске, необходимо создать две или более файловые системы на этом диске.
Всякая файловая система может быть прикреплена (монтирована) к общему дереву каталогов, в любой его точке. Например, каталог / - это корневой (root) каталог системы, кроме этого, он является основанием файловой системы, которая всегда монтирована. Каталог /usr1 находится в каталоге /, но в данном случае является отдельной файловой системой от корневой файловой системы, так как все файлы в нем находятся на отдельной части диска или вообще на отдельном диске. Файловая система /usr1 - монтируемая файловая система - корень в точке, где каталог /usr1 существует в общей иерархии (рис. 1 и 2).
Рис. 1. Файловая система перед
монтированием
/dev/dsk/os1
Рис. 2. Файловая система после
монтирования
/dev/dsk/os1 как /usr/
Для
монтирования файловой системы используется команда /sbin/mount. Эта команда
разрешает расположить данную файловую систему везде в существующей структуре
каталогов:
#/sbin/mount/dev/dsk/osl/usr1
монтирует /dev/dsk/osl на /usr1
#/sbin/mount/dev/dsk/flt/а
монтирует /dev/dsk/flt на /а
Если нужно
монтировать файловую систему на диски, которые должны быть защищены от записи,
чтобы система была доступна только для чтения, необходимо добавить опцию - r к
команде /sbin/mount.
Каталог,
к которому прикрепляется монтируемая файловая система, должен быть в данный
момент пустой, так как содержимое его будет недоступно, пока файловая система
монтируется.
Чтобы получить информацию о файловых системах, которые смонтированы, например, на системе LINUX, можно использовать команду /sbin/mount без аргументов (рис. 3).
Рис. 3.
Эта команда
выводит каталог, на который была смонтирована файловая система (например,
usrl), устройство /dev, на котором она находится, час и дата, когда она была
смонтирована. Для демонтирования файловой системы используется команда
/sbin/umount, которая имеет обратное действие по отношению к команде mount. Она
освобождает файловую систему и как бы вынимает ее целиком из структуры
каталогов, так что все ее собственные файлы и каталоги становятся недоступны:
#
/sbin/umount /b
#
/sbin/umount /dev/dsk/0s2
Корневая файловая система не может быть демонтирована. Кроме того, команда umount не будет выполнена, если кто-нибудь использует файл из той файловой системы, которую пытаются демонтировать (это может быть даже простое пребывание пользователя в одном из каталогов демонтируемой файловой системы).
В командах
mount и umount пользователь использует аббревиатуру физических дисковых
устройств.
В LINUX
дисковые устройства имеют своеобразные обозначения. В LINUX пользователь
никогда не сталкивается с проблемой точного указания физического устройства, на
котором располагается информация. В LINUX произвольное число внешних устройств
может быть очень большим, поэтому, пользователь имеет дело только с именем
каталога, в котором находятся нужные ему файлы. Все файловые системы монтируются
один раз, как правило, при загрузке системы. На некоторые каталоги могут быть
смонтированы файловые системы и с удаленных компьютеров.
Для физических
устройств в LINUX существуют директории dsk и rdsk, которые содержат файлы,
соответствующие дисковым устройствам. Обыкновенно имена файлов в этих
директориях одинаковы и единственная разница между ними, что директория rdsk
содержит дисковые устройства со специальным доступом (raw), который используют
некоторые устройства системы для более быстрого доступа к диску. Одна типичная
директория dsk содержит следующие устройства:
$ 1s
/dev/dsk
0s0 1s0
c0t0d0s0 c0tld0s0 f0 f05q f13dt fld8d
0sl 1sl
c0t0d0sl c0tld0sl f03d f05qt f13h fld8dt
0s2 1s2
c0t0d0s2 c0tld0s2 f03dt f0d8d f13ht fld8t
. . .
$
B системе LINUX дисковые устройства логически разделены на секции, подобно разделам определяемым в Partition Table MasterBoot MS DOS. Файлы 0s1, 0s2, 0s3 и т. д, соответствуют секциям первой, второй, третьей и т. д. диска с номером 0. Файлы 1s0, 1sl, 1s2 и т. д. соответствуют секциям первой, второй, третьей и т. д. диска с номером 1. Если система имеет больше дисков, секции будут пронумерованы ns0, nsl и т. д. для каждого диска с номером n.
Системы с
большим количеством дисковых устройств используют следующую систему нумерации:
с
controller d disk s section
где controller
- номер контроллера диска; disk - номер диска; section -номер секции диска.
Так, 0s0
обычно эквивалентно c0t0d0s0, а 0sl - c0t0d0sl, и трехсимвольные имена секций -
это просто сокращение для дискового контроллера с номером 0.
Файлы, имена
которых начинаются с f, определяют различные виды гибких дисков. Каталог rmt
содержит файлы на устройствах типа магнитная лента:
$ 1s
/dev/rmt
c0s0 cls0
c3s0 ntape ntapel tape tapel
Файлы c0s0, cls0, c2s0 и c3s0 определяют четыре кассетных ленточных запоминающих устройства. Файлы tape и tapel определяют магнитные запоминающие устройства с двумя бобинами. Файлы, чьи имена начинаются с n, относятся к тем же устройствам, только лента не перематывается после использования, в то время как использование других файлов заставляет ленту перематываться, когда использующая ее программа заканчивает работу.
В некоторых системах эти файлы имеют другие названия, однако все они всегда находятся в /dev и словарь, который обычно приходит с системой, содержит подробное описание устройств и связанных с ними файлов.
Файловая система extX при операциях ввода/вывода использует буферизацию данных. При считывании блока информации ядро выдает запрос операции ввода/вывода на несколько расположенных рядом блоков. Такие операции сильно ускоряют извлечение данных при последовательном считывании файлов. При занесении данных в файл файловая система extX, записывая новый блок, заранее размещает рядом до 8 смежных блоков. Такой метод позволяет размещать файлы в смежных блоках, что ускоряет их чтение и дает возможность достичь высокой производительности системы.
Одна из самых интересных и полезных тем для системных администраторов и новых пользователей, которые только начинают разбираться в работе с терминалом - это перенаправление потоков ввода вывода Linux. Эта особенность терминала позволяет перенаправлять вывод команд в файл, или содержимое файла на ввод команды, объединять команды вместе, и образовать конвейеры команд.
В этой статье мы рассмотрим как выполняется перенаправление потоков ввода вывода в Linux, какие операторы для этого используются, а также где все это можно применять.
Все команды, которые мы выполняем, возвращают нам три вида данных:
- Результат выполнения команды, обычно текстовые данные, которые запросил пользователь;
- Сообщения об ошибках - информируют о процессе выполнения команды и возникших непредвиденных обстоятельствах;
- Код возврата - число, которое позволяет оценить правильно ли отработала программа.
В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux - файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла:
- STDIN или 0 - этот файл связан с клавиатурой и большинство команд получают данные для работы отсюда;
- STDOUT или 1 - это стандартный вывод, сюда программа отправляет все результаты своей работы. Он связан с экраном, или если быть точным, то с терминалом, в котором выполняется программа;
- STDERR или 2 - все сообщения об ошибках выводятся в этот файл.
Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов "<" и ">" .
Перенаправить вывод в файл
Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top:
top -bn 5 > top.log
Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n - повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat:

Символ ">" перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте ">>" . Например, перенаправить вывод в файл linux еще для top:
top -bn 5 >> top.log
По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат:
top -bn 5 1>top.log
Перенаправить ошибки в файл
Чтобы перенаправить вывод ошибок в файл вам нужно явно указать дескриптор файла, который собираетесь перенаправлять. Для ошибок - это номер 2. Например, при попытке получения доступа к каталогу суперпользователя ls выдаст ошибку:

Вы можете перенаправить стандартный поток ошибок в файл так:
ls -l /root/ 2> ls-error.log
$ cat ls-error.log

Чтобы добавить данные в конец файла используйте тот же символ:
ls -l /root/ 2>>ls-error.log

Перенаправить стандартный вывод и ошибки в файл
Вы также можете перенаправить весь вывод, ошибки и стандартный поток вывода в один файл. Для этого есть два способа. Первый из них, более старый, состоит в том, чтобы передать оба дескриптора:
ls -l /root/ >ls-error.log 2>&1

Сначала будет отправлен вывод команды ls в файл ls-error.log c помощью первого символа перенаправления. Дальше в тот же самый файл будут направлены все ошибки. Второй метод проще:
ls -l /root/ &> ls-error.log
Также можно использовать добавление вместо перезаписи:
ls -l /root/ &>> ls-error.log
Стандартный ввод из файла
Большинство программ, кроме сервисов, получают данные для своей работы через стандартный ввод. По умолчанию стандартный ввод ожидает данных от клавиатуры. Но вы можете заставить программу читать данные из файла с помощью оператора "<" :
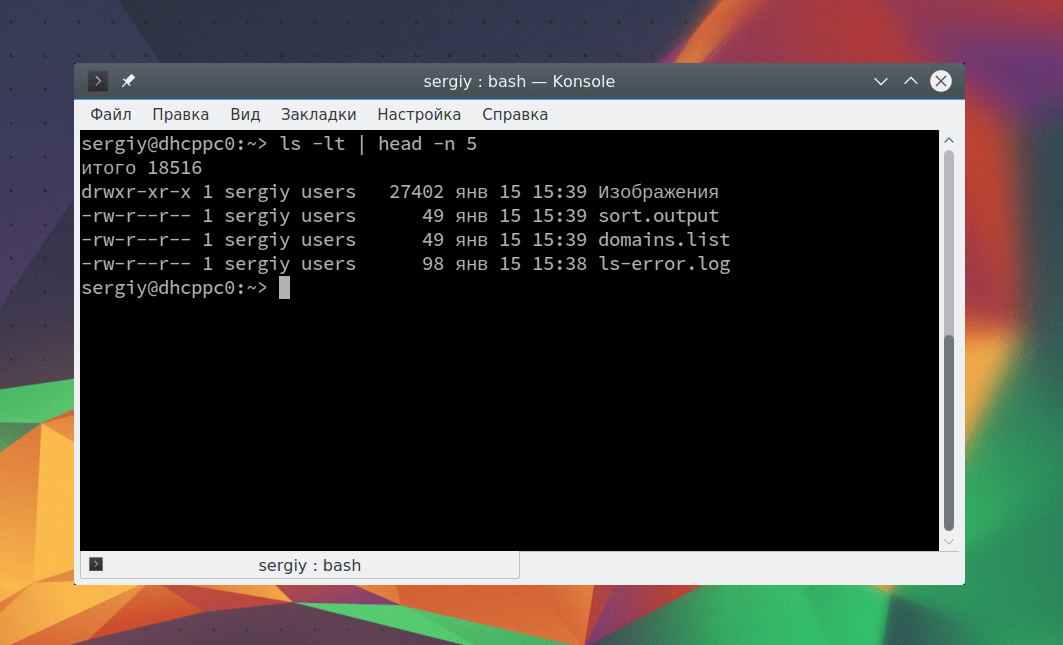
cat Вы также можете сразу же перенаправить вывод тоже в файл. Например, пересортируем список: sort Таким образом, мы в одной команде перенаправляем ввод вывод linux. Можно работать не только с файлами, но и перенаправлять вывод одной команды в качестве ввода другой. Это очень полезно для выполнения сложных операций. Например, выведем пять недавно измененных файлов: ls -lt | head -n 5 С помощью утилиты xargs вы можете комбинировать команды таким образом, чтобы стандартный ввод передавался в параметры. Например, скопируем один файл в несколько папок: echo test/ tmp/ | xargs -n 1 cp -v testfile.sh Здесь параметр -n 1 задает, что для одной команды нужно подставлять только один параметр, а опция -v в cp позволяет выводить подробную информацию о перемещениях. Еще одна, полезная в таких случаях команда - это tee. Она читает данные из стандартного ввода и записывает в стандартный вывод или файлы. Например: echo "Тест работы tee" | tee file1 В сочетании с другими командами все это может использоваться для создания сложных инструкций из нескольких команд. В этой статье мы рассмотрели основы перенаправления потоков ввода вывода Linux. Теперь вы знаете как перенаправить вывод в файл linux или вывод из файла. Это очень просто и удобно. Если у вас остались вопросы, спрашивайте в комментариях! Если вы уже освоились с основами терминала, возможно, вы уже готовы к тому, чтобы комбинировать изученные команды. Иногда выполнения команд оболочки по одной вполне достаточно для решения некоей задачи, но в некоторых случаях вводить команду за командой слишком утомительно и нерационально. В подобной ситуации нам пригодятся некоторые особые символы, вроде угловых скобок. Для оболочки, интерпретатора команд Linux, эти дополнительные символы - не пустая трата места на экране. Они - мощные команды, которые могут связывать воедино различные фрагменты информации, разделять то, что было до этого цельным, и делать ещё много всего. Одна из самых простых, и, в то же время, мощных и широко используемых возможностей оболочки - это перенаправление стандартных потоков ввода/вывода. Первый - это стандартный поток ввода (standard input). В системе это - поток №0 (так как в компьютерах счёт обычно начинается с нуля). Номера потоков ещё называют дескрипторами. Этот поток представляет собой некую информацию, передаваемую в терминал, в частности - инструкции, переданные в оболочку для выполнения. Обычно данные в этот поток попадают в ходе ввода их пользователем с клавиатуры. Второй поток - это стандартный поток вывода (standard output), ему присвоен номер 1. Это поток данных, которые оболочка выводит после выполнения каких-то действий. Обычно эти данные попадают в то же окно терминала, где была введена команда, вызвавшая их появление. И, наконец, третий поток - это стандартный поток ошибок (standard error), он имеет дескриптор 2. Этот поток похож на стандартный поток вывода, так как обычно то, что в него попадает, оказывается на экране терминала. Однако, он, по своей сути, отличается от стандартного вывода, как результат, этими потоками, при желании, можно управлять раздельно. Это полезно, например, в следующей ситуации. Есть команда, которая обрабатывает большой объём данных, выполняя сложную и подверженную ошибкам операцию. Нужно, чтобы полезные данные, которые генерирует эта команда, не смешивались с сообщениями об ошибках. Реализуется это благодаря раздельному перенаправлению потоков вывода и ошибок. Как вы, вероятно, уже догадались, перенаправление ввода/вывода означает работу с вышеописанными потоками и перенаправление данных туда, куда нужно программисту. Делается это с использованием символов > и < в различных комбинациях, применение которых зависит от того, куда, в итоге, должны попасть перенаправляемые данные. При использовании перенаправления любой файл, указанный после > будет перезаписан. Если в файле нет ничего ценного и его содержимое можно потерять, в нашей конструкции допустимо использовать уже существующий файл. Обычно же лучше использовать в подобном случае имя файла, которого пока не существует. Этот файл будет создан после выполнения команды. Назовём его date.txt . Расширение файла после точки обычно особой роли не играет, но расширения помогают поддерживать порядок. Итак, вот наша команда: $ date > date.txt
Так как файл с датой у нас уже есть, будет вполне оправдано просто присоединить к этому файлу данные, полученные от traceroute . Для того, чтобы это сделать, надо использовать два символа > , поставленные один за другим. В результате новая команда, перенаправляющая вывод в файл, но не перезаписывающая его, а добавляющая новые данные после старых, будет выглядеть так: $ traceroute google.com >> date.txt
$ mv date.txt trace1.txt
Предположим, имеется два файла: list1.txt и list2.txt , каждый из которых содержит неотсортированный список строк. В каждом из списков имеются уникальные для него элементы, но некоторые из элементов список совпадают. Мы можем найти строки, которые имеются и в первом, и во втором списках, применив команду comm , но прежде чем её использовать, списки надо отсортировать. Существует команда sort , которая возвращает отсортированный список в терминал, не сохраняя отсортированные данные в файл, из которого они были взяты. Можно отправить отсортированную версию каждого списка в новый файл, используя команду > , а затем воспользоваться командой comm . Однако, такой подход потребует как минимум двух команд, хотя то же самое можно сделать в одной строке, не создавая при этом ненужных файлов. Итак, мы можем воспользоваться командой < для перенаправления отсортированной версии каждого файла команде comm . Вот что у нас получилось: $ comm <(sort list1.txt) <(sort list2.txt)
Например, что если надо провести поиск во всей системе сведений о беспроводных интерфейсах, которые доступны пользователям, у которых нет прав суперпользователя? Для того, чтобы это сделать, можно воспользоваться мощной командой find . Обычно, когда обычный пользователь запускает команду find по всей системе, она выводит в терминал и полезные данные и ошибки. При этом, последних обычно больше, чем первых, что усложняет нахождение в выводе команды того, что нужно. Решить эту проблему довольно просто: достаточно перенаправить стандартный поток ошибок в файл, используя команду 2> (напомним, 2 - это дескриптор стандартного потока ошибок). В результате на экран попадёт только то, что команда отправляет в стандартный вывод: $ find / -name wireless 2> denied.txt
$ find / -name wireless 2> denied.txt > found.txt
И, наконец, если нужно, чтобы всё, что выведет команда, попало в один файл, можно перенаправить оба потока в одно и то же место, воспользовавшись командой &> : $ find / -name wireless &> results.txt
Уважаемые читатели! Знаете ли вы интересные примеры использования перенаправления потоков в Linux, которые помогут новичкам лучше освоиться с этим приёмом работы в терминале? Хотя обычно, как было сказано, ввод/вывод
программы связаны со стандартными потоками, в оболочке существуют
специальные средства для перенаправления ввода/вывода. Для обозначения перенаправления используются
символы ">
", "<
" и ">>
". Чаще
всего используется перенаправление вывода команды в файл. Вот
соответствующий пример: $
ls -l > /home/jim/dir.txt
По этой команде в файле /home/jim/dir.txt будет
сохранен перечень файлов и подкаталогов того каталога, который был
текущим на момент выполнения команды ls
;
при этом если указанного файла не существовало, то он будет создан;
если он существовал, то будет перезаписан; если же вы хотите, чтобы
вывод команды был дописан в конец существующего файла, то надо вместо
символа >
использовать >>
.
При этом наличие пробелов до или после символов >
или >>
несущественно и служит только для удобства пользователя. Вы можете направить вывод не только в файл, но и
на вход другой команды или на устройство (например, принтер). Так,
для подсчета числа слов в файле /home/jim/report.txt можно
использовать следующую команду: $
cat /home/jim/report.txt > wc -w
а для вывода файла на печать — команду: $
cat /home/jim/report.txt > lpr
Как видите, оператор >
служит для
перенаправления выходного потока. По отношению к входному потоку
аналогичную функцию выполняет оператор <
.
Приведенный выше пример команды для подсчета числа слов в
определенном файле можно переписать следующим образом (обратите
внимание на отсутствие команды cat
): $
wc -w < /home/jim/report.txt
Этот вариант перенаправления часто используется в
различных скриптах, применительно к тем командам, которые обычно
воспринимают ввод (или ожидают ввода) с клавиатуры. В скрипте же,
автоматизирующем какие-то рутинные операции, можно дать команде
необходимую информацию из файла, в который заранее записано то, что
нужно ввести для выполнения этой команды. В силу того, что символы <
,
>
и >>
действуют на стандартные потоки, их можно использовать не только тем
привычным образом, как это делается обычно, но и несколько
по-другому. Так, следующие команды эквивалентны: $
cat > file
$
cat>file
$
>file cat
$
> file cat
Однако сам по себе (без какой-либо команды, для
которой определены стандартные потоки) символ перенаправления не
может использоваться, так что нельзя, например, введя в командной
строке $
file1 > file2
получить копию какого-то файла. Но это не
уменьшает значения данного механизма, ведь стандартные потоки
определены для любой команды. При этом перенаправить можно не только
стандартный ввод и вывод, но и другие потоки. Для этого надо указать
перед символом перенаправления номер перенаправляемого потока.
Стандартный ввод stdin имеет номер 0,
стандартный вывод stdout — номер
1, стандартный поток сообщений об ошибках stderr —
номер 2. То есть полный формат команды перенаправления имеет
вид (напомним, что пробелы возле > не обязательны): command
N > M
где N
и M
—
номера стандартных потоков (0,1,2) или имена файлов. Употребление в
некоторых случаях символов <
,
>
и>>
без указания номера канала или имени файла возможно только потому,
что вместо отсутствующего номера по умолчанию подставляется 1, т. е.
стандартный вывод. Так, оператор >
без указания номера интерпретируется как 1
>
. Кроме простого перенаправления стандартных потоков
существует еще возможность не просто перенаправить поток в тот или
иной канал, а сделать копию содержимого стандартного потока. Для
этого служит специальный символ &
,
который ставится перед номером канала, на который перенаправляется
поток: command
N > &M
Такая команда означает, что выход канала с номером
N
направляется как на стандартный вывод, так и дублируется в канал с
номером M
.
Например, для того, чтобы сообщения об ошибках дублировались на
стандартный вывод, надо дать команду 2>&1,
в то время как 1>&2
дублирует stdout в stderr. Такая
возможность особенно полезна при перенаправлении вывода в файл, так
как мы тогда одновременно и видим сообщения на экране, и сохраняем их
в файле. Особым вариантом перенаправления вывода является
организация программного канала (иногда называет трубопроводом или
конвейером). Для этого две или несколько команд, таких, что вывод
предыдущей служит вводом для следующей, соединяются (или разделяются,
если вам это больше нравится) символом вертикальной черты —
"|". При этом стандартный выходной поток команды,
расположенной слева от символа |
,
направляется на стандартный ввод программы, расположенной справа от
символа |
.
Например: $
cat myfile | grep Linux | wc -l
Эта строка означает, что вывод команды cat
,
т. е. текст из файла myfile, будет направлен на вход команды
grep
,
которая выделит только строки, содержащие слово "Linux".
Вывод команды grep
будет, в свою очередь, направлен на вход команды wc -l
,
которая подсчитает число таких строк. Программные каналы используются для того, чтобы
скомбинировать несколько маленьких программ, каждая из которых
выполняет только определенные преобразования над своим входным
потоком, для создания обобщенной команды, результатом которой будет
какое-то более сложное преобразование. Надо отметить, что оболочка одновременно вызывает
на выполнение все команды, включенные в конвейер, запуская для каждой
из команд отдельный экземпляр оболочки, так что как только первая
программа начинает что-либо выдавать в свой выходной поток, следующая
команда начинает его обрабатывать. Точно так же каждая следующая
команда выполняет свою операцию, ожидая данных от предыдущей команды
и выдавая свои результаты на вход последующей. Если вы хотите, чтобы
какая-то команда полностью завершилась до начала выполнения
последующей, вы можете использовать в одной строке как символ
конвейера |
,
так и точку с запятой ;
. Перед каждой точкой с запятой
оболочка будет останавливаться и ожидать, пока завершится выполнение
всех предыдущих команд, включенных в конвейер. Статус выхода (логическое значение, возвращаемое
после завершения работы программы) из канала совпадает со статусом
выхода, возвращаемым последней командой конвейера. Перед первой
командой конвейера можно поставить символ "!", тогда статус
выхода из конвейера будет логическим отрицанием статуса выхода из
последней команды. Оболочка ожидает завершения всех команд конвейера,
прежде чем установить возвращаемое значение. Последний из приведенных выше примеров (с командой
grep
)
можно использовать для иллюстрации еще одного важного понятия, а
именно, программы-фильтра. Фильтры — это команды (или
программы), которые воспринимают входной поток данных, производят над
ним некоторые преобразования и выдают результат на стандартный вывод
(откуда его можно перенаправить куда-то еще по желанию пользователя).
К числу команд-фильтров относятся уже упоминавшиеся выше команды cat,
more, less, wc, cmp, diff
,
а также следующие
команды. Таблица
5.1.
Команды-фильтры
Команда
Краткое описание
grep
,
fgrep
,
egrep
Ищут
во входном файле или данных со стандартного ввода строки,
содержащие указанный шаблон, и выдают их на стандартный вывод
Заменяет
во входном потоке все встречающиеся символы, перечисленные в
заданном перечне, на соответствующие символы из второго заданного
перечня
comm
Сравнивает
два файла по строкам и выдает на стандартный вывод 3 колонки: в
одной — строки, которые встречаются только в 1 файле,
во второй — строки, которые встречаются только во 2-ом
файле: и в третьей — строки, имеющиеся в обоих файлах
Форматирует
для печати текстовый файл или содержимое стандартного ввода
sed
Строковый
редактор, использующийся для выполнения некоторых преобразований
над входным потоком данных (берется из файла или со стандартного
ввода)
Особым фильтром является команда tee
,
которая "раздваивает" входной поток, с одной стороны
направляя его на стандартный вывод, а с другой — в файл
(имя которого вы должны задать). Легко видеть, что по своему действию
команда tee
аналогична оператору перенаправления 1>&file
. Возможности фильтров можно существенно расширить
за счет использования регулярных выражений, позволяющих организовать,
например, поиск по различным, зачастую очень сложным, шаблонам. О перенаправлении и фильтрах можно было бы
говорить очень много. Но этот материал имеется в большинстве книг по
UNIX и Linux, например у Петерсена [П1.4]
и Келли-Бутла [П1.8] .
Поэтому ограничимся сказанным, и перейдем к рассмотрению так
называемой среды или окружения, создаваемого оболочкой.

Использование тоннелей


Выводы
Три стандартных потока ввода/вывода
Для того, чтобы понять то, о чём мы будем тут говорить, важно знать, откуда берутся данные, которые можно перенаправлять, и куда они идут. В Linux существует три стандартных потока ввода/вывода данных.Перенаправление стандартного потока вывода
Предположим, вы хотите создать файл, в который будут записаны текущие дата и время. Дело упрощает то, что имеется команда, удачно названная date , которая возвращает то, что нам нужно. Обычно команды выводят данные в стандартный поток вывода. Для того, чтобы эти данные оказались в файле, нужно добавить символ > после команды, перед именем целевого файла. До и после > надо поставить пробел.
Нельзя сказать, что сама по себе эта команда невероятно полезна, однако, основываясь на ней, мы уже можем сделать что-то более интересное. Скажем, вы хотите узнать, как меняются маршруты вашего трафика, идущего через интернет к некоей конечной точке, ежедневно записывая соответствующие данные. В решении этой задачи поможет команда traceroute , которая сообщает подробности о маршруте трафика между нашим компьютером и конечной точкой, задаваемой при вызове команды в виде URL. Данные включают в себя сведения обо всех маршрутизаторах, через которые проходит трафик.
Теперь нам осталось лишь изменить имя файла на что-нибудь более осмысленное, используя команду mv , которой, в качестве первого аргумента, передаётся исходное имя файла, а в качестве второго - новое:Перенаправление стандартного потока ввода
Используя знак < вместо > мы можем перенаправить стандартный ввод, заменив его содержимым файла.
Круглые скобки тут имеют тот же смысл, что и в математике. Оболочка сначала обрабатывает команды в скобках, а затем всё остальное. В нашем примере сначала производится сортировка строк из файлов, а потом то, что получилось, передаётся команде comm , которая затем выводит результат сравнения списков.Перенаправление стандартного потока ошибок
И, наконец, поговорим о перенаправлении стандартного потока ошибок. Это может понадобиться, например, для создания лог-файлов с ошибками или объединения в одном файле сообщений об ошибках и возвращённых некоей командой данных.
Как быть, если нужно сохранить результаты работы команды в отдельный файл, не смешивая эти данные со сведениями об ошибках? Так как потоки можно перенаправлять независимо друг от друга, в конец нашей конструкции можно добавить команду перенаправления стандартного потока вывода в файл:
Обратите внимание на то, что первая угловая скобка идёт с номером - 2> , а вторая без него. Это так из-за того, что стандартный вывод имеет дескриптор 1, и команда > подразумевает перенаправление стандартного вывода, если номер дескриптора не указан.Итоги
Тут мы разобрали лишь основы механизма перенаправления потоков в интерпретаторе командной строки Linux, однако даже то немногое, что вы сегодня узнали, даёт вам практически неограниченные возможности. И, кстати, как и всё остальное, что касается работы в терминале, освоение перенаправления потоков требует практики. Поэтому рекомендуем вам приступить к собственным экспериментам с > и < .5.5.1 Операторы >, < и >>
5.5.2 Оператор |
5.5.3 Фильтры









