Прогнозирование в excel с помощью линии тренда. Линия тренда в Excel на разных графиках
Для наглядной иллюстрации тенденций изменения цены применяется линия тренда. Элемент технического анализа представляет собой геометрическое изображение средних значений анализируемого показателя.
Рассмотрим, как добавить линию тренда на график в Excel.
Добавление линии тренда на график
Для примера возьмем средние цены на нефть с 2000 года из открытых источников. Данные для анализа внесем в таблицу:


Линия тренда в Excel – это график аппроксимирующей функции. Для чего он нужен – для составления прогнозов на основе статистических данных. С этой целью необходимо продлить линию и определить ее значения.
Если R2 = 1, то ошибка аппроксимации равняется нулю. В нашем примере выбор линейной аппроксимации дал низкую достоверность и плохой результат. Прогноз будет неточным.
Внимание!!! Линию тренда нельзя добавить следующим типам графиков и диаграмм:
- лепестковый;
- круговой;
- поверхностный;
- кольцевой;
- объемный;
- с накоплением.
Уравнение линии тренда в Excel
В предложенном выше примере была выбрана линейная аппроксимация только для иллюстрации алгоритма. Как показала величина достоверности, выбор был не совсем удачным.
Следует выбирать тот тип отображения, который наиболее точно проиллюстрирует тенденцию изменений вводимых пользователем данных. Разберемся с вариантами.
Линейная аппроксимация
Ее геометрическое изображение – прямая. Следовательно, линейная аппроксимация применяется для иллюстрации показателя, который растет или уменьшается с постоянной скоростью.
Рассмотрим условное количество заключенных менеджером контрактов на протяжении 10 месяцев:

На основании данных в таблице Excel построим точечную диаграмму (она поможет проиллюстрировать линейный тип):

Выделяем диаграмму – «добавить линию тренда». В параметрах выбираем линейный тип. Добавляем величину достоверности аппроксимации и уравнение линии тренда в Excel (достаточно просто поставить галочки внизу окна «Параметры»).

Получаем результат:

Обратите внимание! При линейном типе аппроксимации точки данных расположены максимально близко к прямой. Данный вид использует следующее уравнение:
y = 4,503x + 6,1333
- где 4,503 – показатель наклона;
- 6,1333 – смещения;
- y – последовательность значений,
- х – номер периода.
Прямая линия на графике отображает стабильный рост качества работы менеджера. Величина достоверности аппроксимации равняется 0,9929, что указывает на хорошее совпадение расчетной прямой с исходными данными. Прогнозы должны получиться точными.
Чтобы спрогнозировать количество заключенных контрактов, например, в 11 периоде, нужно подставить в уравнение число 11 вместо х. В ходе расчетов узнаем, что в 11 периоде этот менеджер заключит 55-56 контрактов.
Экспоненциальная линия тренда
Данный тип будет полезен, если вводимые значения меняются с непрерывно возрастающей скоростью. Экспоненциальная аппроксимация не применяется при наличии нулевых или отрицательных характеристик.
Построим экспоненциальную линию тренда в Excel. Возьмем для примера условные значения полезного отпуска электроэнергии в регионе Х:

Строим график. Добавляем экспоненциальную линию.

Уравнение имеет следующий вид:
y = 7,6403е^-0,084x
- где 7,6403 и -0,084 – константы;
- е – основание натурального логарифма.
Показатель величины достоверности аппроксимации составил 0,938 – кривая соответствует данным, ошибка минимальна, прогнозы будут точными.
Логарифмическая линия тренда в Excel
Используется при следующих изменениях показателя: сначала быстрый рост или убывание, потом – относительная стабильность. Оптимизированная кривая хорошо адаптируется к подобному «поведению» величины. Логарифмический тренд подходит для прогнозирования продаж нового товара, который только вводится на рынок.
На начальном этапе задача производителя – увеличение клиентской базы. Когда у товара будет свой покупатель, его нужно удержать, обслужить.
Построим график и добавим логарифмическую линию тренда для прогноза продаж условного продукта:

R2 близок по значению к 1 (0,9633), что указывает на минимальную ошибку аппроксимации. Спрогнозируем объемы продаж в последующие периоды. Для этого нужно в уравнение вместо х подставлять номер периода.
Например:
| Период | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Прогноз | 1005,4 | 1024,18 | 1041,74 | 1058,24 | 1073,8 | 1088,51 | 1102,47 |
Для расчета прогнозных цифр использовалась формула вида: =272,14*LN(B18)+287,21. Где В18 – номер периода.
Полиномиальная линия тренда в Excel
Данной кривой свойственны переменные возрастание и убывание. Для полиномов (многочленов) определяется степень (по количеству максимальных и минимальных величин). К примеру, один экстремум (минимум и максимум) – это вторая степень, два экстремума – третья степень, три – четвертая.
Полиномиальный тренд в Excel применяется для анализа большого набора данных о нестабильной величине. Посмотрим на примере первого набора значений (цены на нефть).

Чтобы получить такую величину достоверности аппроксимации (0,9256), пришлось поставить 6 степень.
Зато такой тренд позволяет составлять более-менее точные прогнозы.
Диаграммы и графики используются для анализа числовых данных, например, для оценки зависимости меж-ду двумя видами значений. С этой целью к данным диаграммы или графика можно добавить линию тренда и ее уравнение, прогнозные значения, рассчитанные на несколько периодов вперед или назад.
Линия тренда представляет собой прямую или кривую линию, аппроксимирующую (приближающую) исходные данные на основе уравнения регрессии или скользящего среднего. Аппроксимация определяется по ме-тоду наименьших квадратов. В зависимости от характера поведения исходных данных (убыва-ют, возрастают и т.д.) выбирается метод интерполяции, который сле-дует использовать для построения тренда.
Предусмотрено несколько вариантов формирования линии трен-да.
Линейной функцией: y=mx+b
где m — тангенс угла наклона прямой, b — смещение.
Прямая линия тренда (линейный тренд) наилучшим образом подходит для величин, изменяющихся с постоянной скоростью. Приме-няется в случаях, когда точки данных расположены близко к прямой.
Логарифмической функцией: y=c*lnx+b
где с и b — константы.
Логарифмическая линия тренда соответствует ряду данных, значения которого вначале быстро растут или убывают, а затем постепенно стабилизируются. Может использоваться для положительных и отрицательных данных.
Полиномиальной функцией (до 6-й степени включительно): y= b + c 1 *x + c 2 *x 2 + c 3 *x 3 + ...+ c 6* x 6
где b, c 1 , c 2 , ... c 6 — константы.
Полиномиальная линия тренда используется для описания попеременно возрастающих и убывающих данных. Степень полинома подбирают таким образом, чтобы она была на единицу больше количества экстремумов (максимумов и минимумов) кривой.
Степенной функцией: y = cxb
где c и b — константы.
Степенная линия тренда дает хорошие результаты для положительных данных с постоянным ускорением. Для рядов с нулевыми или отрицательными значениями построение указанной линии трен-да невозможно.
Экспоненциальной функцией: y = cebx
где c и b — константы, е — основание натурального логарифма.
Экспоненциальный тренд используется в случае непрерывного возрастания изменения данных. Построение указанного тренда не- возможно, если в множестве значений членов ряда присутствуют нулевые или отрицательные данные.
С использованием линейной фильтрации по формуле: F t = (A t +A (t-1) +⋯+A (t-n+1))/n
где n — общее число членов ряда, t — заданное число точек (2 ≤ t < n).
Тренд с линейной фильтрацией позволяет сгладить колебания данных, наглядно демонстрируя характер зависимостей. Для построения указанной линии тренда пользователь должен задать число — параметр фильтра. Если задано число 2, то первая точка линии трен-да определяется как среднее значение из первых двух элементов данных, вторая точка — как среднее второго и третьего элементов данных и т.д.
Для некоторых типов диаграмм линия тренда в принципе не мо-жет быть построена — диаграмм с накоплением, объемных, лепест-ковых, круговых, поверхностных, кольцевых. При возможности к диаграмме можно добавить несколько линий с разными па-раметрами. Соответствие линии тренда фактическим значениям ряда данных устанавливается с помощью коэффициента достоверности аппрок-симации:
Линия тренда, а также ее параметры добавляются к данным диа-граммы следующими командами:

При необходимости параметры линии можно изменить, вызвав щелчком мыши по ряду данных диаграммы или линии трен-да окно Формат линии тренда. Можно добавить (или удалить) урав-нение регрессии, коэффициент достоверности аппроксимации, оп-ределить направление и прогноз изменения ряда данных, а также выполнить коррекцию оформительских элементов линии тренда. Выделенная линия тренда может быть также удалена.
На рисунке приведена таблица данных по изменению стоимости ценной бумаги. На основе этих условных данных построена точечная диаграмма, добавлена поли-номиальная линия тренда третьего порядка (задана штриховой ли-нией) и некоторые другие параметры. Полученное значение коэф-фициента достоверности аппроксимации R 2 на диаграмме близко к единице, что свидетельствует о близости расчетной линии тренда с данными задачи. Прогнозное значение изменения стоимости ценной бумаги направлено в сторону роста.
Прогнозирование – это очень важный элемент практически любой сферы деятельности, начиная от экономики и заканчивая инженерией. Существует большое количество программного обеспечения, специализирующегося именно на этом направлении. К сожалению, далеко не все пользователи знают, что обычный табличный процессор Excel имеет в своем арсенале инструменты для выполнения прогнозирования, которые по своей эффективности мало чем уступают профессиональным программам. Давайте выясним, что это за инструменты, и как сделать прогноз на практике.
Целью любого прогнозирования является выявление текущей тенденции, и определение предполагаемого результата в отношении изучаемого объекта на определенный момент времени в будущем.
Способ 1: линия тренда
Одним из самых популярных видов графического прогнозирования в Экселе является экстраполяция выполненная построением линии тренда.
Попробуем предсказать сумму прибыли предприятия через 3 года на основе данных по этому показателю за предыдущие 12 лет.

Способ 2: оператор ПРЕДСКАЗ
Экстраполяцию для табличных данных можно произвести через стандартную функцию Эксель ПРЕДСКАЗ . Этот аргумент относится к категории статистических инструментов и имеет следующий синтаксис:
ПРЕДСКАЗ(X;известные_значения_y;известные значения_x)
«X» – это аргумент, значение функции для которого нужно определить. В нашем случае в качестве аргумента будет выступать год, на который следует произвести прогнозирование.
«Известные значения y» — база известных значений функции. В нашем случае в её роли выступает величина прибыли за предыдущие периоды.
«Известные значения x» — это аргументы, которым соответствуют известные значения функции. В их роли у нас выступает нумерация годов, за которые была собрана информация о прибыли предыдущих лет.
Естественно, что в качестве аргумента не обязательно должен выступать временной отрезок. Например, им может являться температура, а значением функции может выступать уровень расширения воды при нагревании.
При вычислении данным способом используется метод линейной регрессии.
Давайте разберем нюансы применения оператора ПРЕДСКАЗ на конкретном примере. Возьмем всю ту же таблицу. Нам нужно будет узнать прогноз прибыли на 2018 год.


Но не стоит забывать, что, как и при построении линии тренда, отрезок времени до прогнозируемого периода не должен превышать 30% от всего срока, за который накапливалась база данных.
Способ 3: оператор ТЕНДЕНЦИЯ
Для прогнозирования можно использовать ещё одну функцию – ТЕНДЕНЦИЯ . Она также относится к категории статистических операторов. Её синтаксис во многом напоминает синтаксис инструмента ПРЕДСКАЗ и выглядит следующим образом:
ТЕНДЕНЦИЯ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы «Известные значения y» и «Известные значения x» полностью соответствуют аналогичным элементам оператора ПРЕДСКАЗ , а аргумент «Новые значения x» соответствует аргументу «X» предыдущего инструмента. Кроме того, у ТЕНДЕНЦИЯ имеется дополнительный аргумент «Константа» , но он не является обязательным и используется только при наличии постоянных факторов.
Данный оператор наиболее эффективно используется при наличии линейной зависимости функции.
Посмотрим, как этот инструмент будет работать все с тем же массивом данных. Чтобы сравнить полученные результаты, точкой прогнозирования определим 2019 год.


Способ 4: оператор РОСТ
Ещё одной функцией, с помощью которой можно производить прогнозирование в Экселе, является оператор РОСТ. Он тоже относится к статистической группе инструментов, но, в отличие от предыдущих, при расчете применяет не метод линейной зависимости, а экспоненциальной. Синтаксис этого инструмента выглядит таким образом:
РОСТ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы у данной функции в точности повторяют аргументы оператора ТЕНДЕНЦИЯ , так что второй раз на их описании останавливаться не будем, а сразу перейдем к применению этого инструмента на практике.


Способ 5: оператор ЛИНЕЙН
Оператор ЛИНЕЙН при вычислении использует метод линейного приближения. Его не стоит путать с методом линейной зависимости, используемым инструментом ТЕНДЕНЦИЯ . Его синтаксис имеет такой вид:
ЛИНЕЙН(Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Последние два аргумента являются необязательными. С первыми же двумя мы знакомы по предыдущим способам. Но вы, наверное, заметили, что в этой функции отсутствует аргумент, указывающий на новые значения. Дело в том, что данный инструмент определяет только изменение величины выручки за единицу периода, который в нашем случае равен одному году, а вот общий итог нам предстоит подсчитать отдельно, прибавив к последнему фактическому значению прибыли результат вычисления оператора ЛИНЕЙН , умноженный на количество лет.


Как видим, прогнозируемая величина прибыли, рассчитанная методом линейного приближения, в 2019 году составит 4614,9 тыс. рублей.
Способ 6: оператор ЛГРФПРИБЛ
Последний инструмент, который мы рассмотрим, будет ЛГРФПРИБЛ . Этот оператор производит расчеты на основе метода экспоненциального приближения. Его синтаксис имеет следующую структуру:
ЛГРФПРИБЛ (Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Как видим, все аргументы полностью повторяют соответствующие элементы предыдущей функции. Алгоритм расчета прогноза немного изменится. Функция рассчитает экспоненциальный тренд, который покажет, во сколько раз поменяется сумма выручки за один период, то есть, за год. Нам нужно будет найти разницу в прибыли между последним фактическим периодом и первым плановым, умножить её на число плановых периодов (3) и прибавить к результату сумму последнего фактического периода.


Прогнозируемая сумма прибыли в 2019 году, которая была рассчитана методом экспоненциального приближения, составит 4639,2 тыс. рублей, что опять не сильно отличается от результатов, полученных при вычислении предыдущими способами.
Мы выяснили, какими способами можно произвести прогнозирование в программе Эксель. Графическим путем это можно сделать через применение линии тренда, а аналитическим – используя целый ряд встроенных статистических функций. В результате обработки идентичных данных этими операторами может получиться разный итог. Но это не удивительно, так как все они используют разные методы расчета. Если колебание небольшое, то все эти варианты, применимые к конкретному случаю, можно считать относительно достоверными.
Глядя на любой набор данных распределенных во времени (динамический ряд), мы можем визуально определить падения и подъемы показателей, которые он содержит. Закономерность подъемов и падений называется трендом, который может говорить о том, увеличиваются или уменьшаются наши данные.
Пожалуй, цикл статей о прогнозировании я начну с самого простого — построении функции тренда. Для примера возьмем данные о продажах и построим модель, которая опишет зависимость продаж от времени.
Базовые понятия
Думаю, еще со школы все знакомы с линейной функцией, она как раз и лежит в основе тренда:
Y(t) = a0 + a1*t + E
Y — это объем продаж, та переменная, которую мы будем объяснять временем и от которого она зависит, то есть Y(t);
t — номер периода (порядковый номер месяца), который объясняет план продаж Y;
a0 — это нулевой коэффициент регрессии, который показывает значение Y(t), при отсутствии влияния объясняющего фактора (t=0);
a1 — коэффициент регрессии, который показывает, на сколько исследуемый показатель продаж Y зависит от влияющего фактора t;
E — случайные возмущения, которые отражают влияния других неучтенных в модели факторов, кроме времени t.
Построение модели
Итак, мы знаем объем продаж за прошедшие 9 месяцев. Вот, что из себя представляет наша табличка:
Следующее, что мы должны сделать — это определить коэффициенты a0 и a1 для прогнозирования объема продаж за 10-ый месяц.
Определение коэффициентов модели
Строим график. По горизонтали видим отложенные месяцы, по вертикали объем продаж:
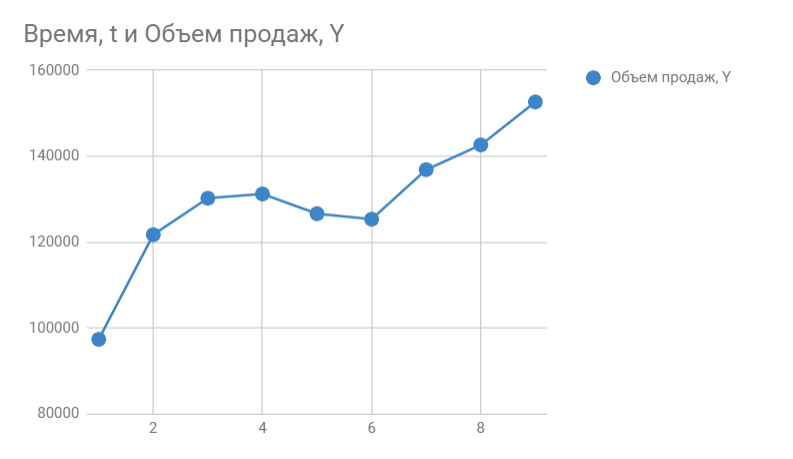
В Google Sheets выбираем Редактор диаграмм -> Дополнительные и ставим галочку возле Линии тренда . В настройках выбираем Ярлык — Уравнение и Показать R^2 .
Если вы делаете все в MS Excel, то правой кнопкой мыши кликаем на график и в выпадающем меню выбираем «Добавить линию тренда».
По умолчанию строится линейная функция. Справа выбираем «Показывать уравнение на диаграмме» и «Величину достоверности аппроксимации R^2».
Вот, что получилось:

На графике мы видим уравнение функции:
y = 4856*x + 105104
Она описывает объем продаж в зависимости от номера месяца, на который мы хотим эти продажи спрогнозировать. Рядом видим коэффициент детерминации R^2, который говорит о качестве модели и на сколько хорошо она описывает наши продажи (Y). Чем ближе к 1, тем лучше.
У меня R^2 = 0,75. Это средний показатель, он говорит о том, что в модели не учтены какие-то другие значимые факторы помимо времени t, например, это может быть сезонность.
Прогнозируем
y = 4856*10 + 105104
Получаем 153664 продажи в следующем месяце. Если добавим новую точку на график, то сразу видим, что R^2 улучшился.

Таким образом вы можете спрогнозировать данные на несколько месяцев вперед, но без учета других факторов ваш прогноз будет лежать на линии тренда и будет не таким информативным как хотелось бы. К тому же, долгосрочный прогноз, сделанный таким способом будет очень приблизительным.
Повысить точность модели можно добавлением сезонности к функции тренда, что мы и сделаем в следующей статье.
Наиболее часто тренд представляется линейной зависимостью исследуемой величины вида
где y – исследуемая переменная (например, производительность) или зависимая переменная;
x – число, определяющее позицию (второй, третий и т.д.) года в периоде прогнозирования или независимая переменная.
При линейной аппроксимации связи между двумя параметрами для нахождения эмпирических коэффициентов линейной функции используется наиболее часто метод наименьших квадратов. Суть метода состоит в том, что линейная функция «наилучшего соответствия» проходит через точки графика, соответствующие минимуму суммы квадратов отклонений измеряемого параметра. Такое условие имеет вид:

где n – объем исследуемой совокупности (число единиц наблюдений).

Рис. 5.3. Построение тренда методом наименьших квадратов
Значения констант b и a или коэффициента при переменной Х и свободного члена уравнения определяются по формуле:

В табл. 5.1 приведен пример вычисления линейного тренда по данным .
Таблица 5.1. Вычисление линейного тренда

Методы сглаживания колебаний.
При сильных расхождениях между соседними значениями тренд, полученный методом регрессии, трудно поддается анализу. При прогнозировании, когда ряд содержит данные с большим разбросом колебаний соседних значений, следует их сгладить по определенным правилам, а потом искать смысл в прогнозе. К методу сглаживания колебаний
относят: метод скользящих средних (рассчитывается n-точечное среднее), метод экспоненциального сглаживания. Рассмотрим их.
Метод «скользящих средних» (МСС).
МСС позволяет сгладить ряд значений с тем, чтобы выделить тренд. При использовании этого метода берется среднее (обычно среднеарифметическое) фиксированного числа значений. Например, трехточечное скользящее среднее. Берется первая тройка значений, составленная из данных за январь, февраль и март (10 + 12 + 13), и определяется среднее, равное 35: 3 = 11,67.
Полученное значение 11,67 ставится в центре диапазона, т.е. по строке февраля. Затем «скользим на один месяц» и берется вторая тройка чисел, начиная с февраля по апрель (12 + 13 + 16), и рассчитывается среднее, равное 41: 3 = 13,67, и таким приемом обрабатываем данные по всему ряду. Полученные средние представляют новый ряд данных для построения тренда и его аппроксимации. Чем больше берется точек для вычисления скользящей средней, тем сильнее происходит сглаживание колебаний. Пример из МВА построения тренда дан в табл. 5.2 и на рис. 5.4.
Таблица 5.2 Расчет тренда методом трехточечного скользящего среднего

Характер колебаний исходных данных и данных, полученных методом скользящего среднего, иллюстрирован на рис. 5.4. Из сравнения графиков рядов исходных значений (ряд 3) и трехточечных скользящих средних (ряд 4), видно, что колебания удается сгладить. Чем большее число точек будет вовлекаться в диапазон вычисления скользящей средней, тем нагляднее будет вырисовываться тренд (ряд 1). Но процедура укрупнения диапазона приводит к сокращению числа конечных значений и это снижает точность прогноза.
Прогнозы следует делать исходя из оценок линии регрессии, составленной по значениям исходных данных или скользящих средних.

Рис. 5.4. Характер изменения объема продаж по месяцам года:
исходные данные (ряд 3); скользящие средние (ряд 4); экспоненциальное сглаживание (ряд 2); тренд, построенный методом регрессии (ряд 1)
Метод экспоненциального сглаживания.
Альтернативный подход к сокращению разброса значений ряда состоит в использовании метода экспоненциального сглаживания. Метод получил название «экспоненциальное сглаживание» в связи с тем, что каждое значение периодов, уходящих в прошлое, уменьшается на множитель (1 – α).
Каждое сглаженное значение рассчитывается по формуле вида:
St =aYt +(1−α)St−1,
где St – текущее сглаженное значение;
Yt – текущее значение временного ряда; St – 1 – предыдущее сглаженное значение; α – сглаживающая константа, 0 ≤ α ≤ 1.
Чем меньше значение константы α , тем менее оно чувствительно к изменениям тренда в данном временном ряду.
-
 17 апреля 2015Многоядерный DSP TMS320C6678
17 апреля 2015Многоядерный DSP TMS320C6678 -
 17 апреля 2015Продукция Intel: чипсеты и их особенности
17 апреля 2015Продукция Intel: чипсеты и их особенности




: лёгкий, удобный, мощный")


