2 critérios. P.2
Aula 6. Análise de duas amostras
6.1 Critérios paramétricos. 1
6.1.2 Teste t de Student ( teste t) 2
6.1.3 F - Critério de Fisher. 6
6.2 Testes não paramétricos. 7
6.2.1 Critério de sinalização ( Critério G) 7
A próxima tarefa da análise estatística, resolvida após a determinação das características principais (da amostra) e a análise de uma amostra, é a análise conjunta de várias amostras. A questão mais importante que surge ao analisar duas amostras é se existem diferenças entre as amostras. Normalmente, isso é feito testando hipóteses estatísticas sobre a pertença de ambas as amostras à mesma população geral ou sobre a igualdade de médias.
Se nos for dado o tipo de distribuição ou função de distribuição da amostra, então, neste caso, o problema de avaliar as diferenças entre dois grupos de observações independentes pode ser resolvido usando paramétrico critério estatísticas: teste de estudante ( t ), se as amostras forem comparadas usando valores médios ( X e U), ou usando o critério de Fisher ( F ), se as amostras forem comparadas com base em suas variações.
Usar critérios estatísticos paramétricos sem primeiro verificar o tipo de distribuição pode levar a certos errosdurante o teste da hipótese de trabalho.
Para superar essas dificuldades na prática da pesquisa pedagógica, deve-se utilizar não paramétrico critério Estatisticas , como teste de sinais, teste de Wilcoxon para duas amostras, teste de Van der Waerden, teste de Spearman, cuja escolha, embora não exija grande número de membros da amostra e conhecimento, o tipo de distribuição, ainda depende de um número de condições.
Testes estatísticos não paramétricos - estão livres do pressuposto da lei de distribuição das amostras e baseiam-se no pressuposto da independência das observações.
6.1 Critérios paramétricos
Para o grupo critérios paramétricos métodos de estatística matemática inclui métodos de cálculo de estatísticas descritivas, construção de gráficos de normalidade de distribuição, teste de hipóteses sobre o pertencimento de duas amostras à mesma população. Esses métodos baseiam-se na suposição de que a distribuição da amostra segue uma lei de distribuição normal (Gaussiana). Dentre os critérios da estatística paramétrica, consideraremos os testes de Student e Fisher.
6.1.1 Métodos para testar amostras quanto à normalidade
Para determinar se estamos lidando com uma distribuição normal, os seguintes métodos podem ser usados:
1) dentro dos eixos você pode desenhar um polígono de frequência (função de distribuição empírica) e curva de sino com base em dados de pesquisa. Ao examinar as formas da curva de distribuição normal e o gráfico da função de distribuição empírica, pode-se descobrir os parâmetros pelos quais a última curva difere da primeira;
2) calculado média mediana e moda, e com base nisso é determinado o desvio da distribuição normal. Se a moda, a mediana e a média aritmética não diferirem significativamente entre si, estamos lidando com uma distribuição normal. Se a mediana diferir significativamente da média, estamos lidando com uma amostra assimétrica.
3) a curtose da curva de distribuição deve ser igual a 0. As curvas com curtose positiva são significativamente mais verticais que a curva de distribuição normal. As curvas com curtose negativa são mais inclinadas do que uma curva de distribuição normal;
4) após determinar o valor médio da distribuição de frequência e desvio padrão, encontre os quatro intervalos de distribuição a seguir e compare-os com os dados reais da série:
a) - o intervalo deve incluir cerca de 25% da frequência populacional,
b) - o intervalo deve incluir cerca de 50% da frequência populacional,
c) - o intervalo deve incluir cerca de 75% da frequência populacional,
d) - o intervalo deve incluir cerca de 100% da frequência populacional.
6.1.2 Teste t de Student ( teste t)
O teste permite encontrar a probabilidade de ambas as médias da amostra pertencerem à mesma população. Este critério é mais frequentemente usado para testar a hipótese: “As médias de duas amostras pertencem à mesma população”.
Ao utilizar o critério, dois casos podem ser distinguidos. No primeiro caso, é utilizado para testar a hipótese sobre a igualdade das médias gerais de dois independente, não relacionado amostras (chamadas duas amostras teste t). Neste caso, existe um grupo controle e um grupo experimental (experimental), o número de sujeitos nos grupos pode ser diferente;
No segundo caso, quando o mesmo grupo de objetos gera material numérico para testar hipóteses sobre médias, ocorre o chamado teste t pareado. As amostras são chamadas dependente, relacionado.
a) caso de amostras independentes
A estatística de teste para o caso de amostras independentes e não relacionadas é:
onde , são médias aritméticas nos grupos experimental e controle,
Erro padrão da diferença entre médias aritméticas. Encontrado a partir da fórmula:
![]() ,(2)
,(2)
onde n 1 e n 2 os valores da primeira e segunda amostras, respectivamente.
Se n 1 =n 2, então o erro padrão da diferença entre as médias aritméticas será calculado de acordo com a fórmula:
 (3)
(3)
onde n é o tamanho da amostra.
Contar número de graus de liberdade realizado de acordo com a fórmula:
k = n 1 + n 2 – 2.(4)
Se as amostras forem numericamente iguais, k = 2 n - 2.
Em seguida, você precisa comparar o valor t em obtido com o valor teórico da distribuição t de Student (consulte o apêndice dos livros didáticos de estatística). Se você Vejamos um exemplo de uso t -Teste t de Student para amostras não conectadas e de tamanhos desiguais. Exemplo 1. Em dois grupos de alunos - experimental e controle - foram obtidos os seguintes resultados na disciplina acadêmica (pontuações nos testes; ver Tabela 1). Tabela 1. Resultados do experimento Primeiro grupo (experimental) N 1 =11 pessoas Segundo grupo (controle) N 2 =9 pessoas 121413161191315151814 Número total de membros da amostra: n 1 =11, n 2 =9. Cálculo de médias aritméticas: X av =13,636; Y av = 9,444 Desvio padrão: s x =2,460; s y =2,186 Usando a fórmula (2), calculamos o erro padrão da diferença entre as médias aritméticas:
Calculamos as estatísticas do critério:
Comparamos o valor t obtido no experimento com o valor da tabela, levando em consideração os graus de liberdade iguais, conforme fórmula (4), ao número de sujeitos menos dois (18). O valor tabulado de t crit é igual a 2,1, assumindo o risco de fazer um julgamento errado em cinco casos entre cem (nível de significância = 5% ou 0,05). Se o valor t empírico obtido na experiência exceder o tabelado, então há motivos para aceitar a hipótese alternativa (H 1) de que os alunos do grupo experimental apresentam, em média, um nível de conhecimento superior. No experimento t=3,981, tabela t=2,10, 3,981>2,10, o que leva à conclusão sobre a vantagem do aprendizado experimental. Aqui pode haver tal questões
: 1. E se o valor t obtido no experimento for menor que o tabelado? Então devemos aceitar a hipótese nula. 2. A vantagem do método experimental foi comprovada? Não está tanto comprovado quanto mostrado, porque desde o início existe o risco de errar em cinco casos em cem (p = 0,05). Nosso experimento poderia ser um desses cinco casos. Mas 95% dos casos possíveis falam a favor da hipótese alternativa, e este é um argumento bastante convincente na prova estatística. 3. E se o grupo de controle tiver um desempenho melhor que o grupo experimental? Por exemplo, vamos trocar de lugar, fazendo a média aritmética do grupo experimental, a - o controle:
Daí resulta que o novo método ainda não provou ser bom, talvez por várias razões. Como o valor absoluto é 3,9811>2,1, aceita-se a segunda hipótese alternativa (H 2) sobre a vantagem do método tradicional. No caso de amostras relacionadas com um número igual de medições em cada uma, você pode usar a fórmula mais simples do teste t de Student. O valor t é calculado usando a fórmula: onde estão as diferenças entre os valores correspondentes da variável X e da variável Y, e d é a média dessas diferenças; Sd é calculado usando a seguinte fórmula:
Número de graus de liberdade k determinado pela fórmula k=n -1. Vamos considerar um exemplo de uso do teste t de Student para amostras conectadas e, obviamente, iguais em número. Se você Exemplo 2. Foi estudado o nível de orientação dos alunos para os valores artísticos e estéticos. Para intensificar a formação dessa orientação, foram realizadas conversas no grupo experimental, realizadas exposições de desenhos infantis, organizadas visitas a museus e galerias de arte, realizados encontros com músicos, artistas, etc. a eficácia do trabalho realizado? Para verificar a eficácia deste trabalho, foi realizado um teste antes e depois do experimento. Por razões metodológicas, a Tabela 2 mostra os resultados de um pequeno número de sujeitos. Tabela 2. Resultados experimentais Alunos (n=10) Pontos Cálculos auxiliares
antes do início do experimento (X)
no final experimento (você)
d d2 Ivanov Novikov Sidorov Pirogov Ágape Suvorov Ryzhikov Serov Toporov Bystrov Média 14,8
21,1
Primeiro, vamos calcular usando a fórmula:
Então aplicamos a fórmula (6), obtemos: E finalmente, a fórmula (5) deve ser aplicada. Nós temos:
Número de graus de liberdade: k =10-1=9 e de acordo com a tabela do Apêndice 1 encontramos t crit =2,262, experimental t=6,678, o que implica a possibilidade de aceitar uma hipótese alternativa (H 1) sobre diferenças significativas em meios aritméticos, ou seja, é feita uma conclusão sobre a eficácia da influência experimental. Em termos de hipóteses estatísticas, o resultado obtido será o seguinte: ao nível de 5%, a hipótese H 0 é rejeitada e a hipótese H 1 é aceite. Critério de Fisher permite comparar as variações amostrais de duas amostras independentes. Para calcular F emp, você precisa encontrar a razão entre as variâncias de duas amostras, de modo que a maior variância esteja no numerador e a menor esteja no denominador. A fórmula para calcular o critério de Fisher é: onde estão as variâncias da primeira e segunda amostras, respectivamente. Como, pelas condições do critério, o valor do numerador deve ser maior ou igual ao valor do denominador, o valor de F emp será sempre maior ou igual a um. O número de graus de liberdade também é determinado de forma simples: k 1 =n eu - 1 para a primeira amostra (ou seja, para a amostra cuja variância é maior) e k 2 =n 2 - 1 para a segunda amostra. No Apêndice 1, os valores críticos do critério de Fisher são encontrados pelos valores de k 1 (linha superior da tabela) e k 2 (coluna esquerda da tabela). Se t em >t crit, então a hipótese nula é aceita, caso contrário a alternativa é aceita. Exemplo 3. Em duas terceiras séries, dez alunos foram testados quanto ao desenvolvimento mental usando o teste TURMSH. Os valores médios obtidos não diferiram significativamente, mas a psicóloga está interessada em saber se existem diferenças no grau de homogeneidade dos indicadores de desenvolvimento mental entre as classes. Solução. Para o teste de Fisher, é necessário comparar as variâncias dos resultados dos testes nas duas classes. Os resultados do teste são apresentados na tabela: Tabela 3. Nº de alunos Primeira série Segunda classe Valores Média 60,6
63,6
Calculadas as variâncias para as variáveis X e Y, obtemos: s x 2 =572,83; s 2 =174,04 Então, utilizando a fórmula (8) para cálculo pelo critério F de Fisher, encontramos:
De acordo com a tabela do Apêndice 1 para o critério F com graus de liberdade em ambos os casos iguais a k = 10 - 1 = 9, encontramos F crit = 3,18 (<3.29), следовательно, в терминах
статистических гипотез можно утверждать,
что Н 0 (гипотеза о сходстве) может быть
отвергнута на уровне 5%, а принимается в этом
случае гипотеза Н 1 . Иc
следователь
может утверждать, что по степени
однородности такого показателя, как
умственное развитие, имеется различие
между выборками из двух классов. Ao comparar a olho nu (em percentagem) os resultados antes e depois de qualquer impacto, o investigador chega à conclusão de que se forem observadas diferenças, então há uma diferença nas amostras que estão a ser comparadas. Esta abordagem é categoricamente inaceitável, uma vez que para percentagens é impossível determinar o nível de fiabilidade nas diferenças. As percentagens tomadas por si só não permitem tirar conclusões estatisticamente fiáveis. Para comprovar a eficácia de qualquer intervenção, é necessário identificar uma tendência estatisticamente significativa no viés (mudança) dos indicadores. Para resolver tais problemas, o pesquisador pode utilizar uma série de critérios de diferença que serão considerados a seguir: o teste do sinal e o teste do qui-quadrado. O critério tem como objetivo comparar o estado de alguma propriedade entre membros de dois dependente
amostras com base em medições feitas em uma escala não inferior à da classificação. Existem duas séries de observações sobre variáveis aleatórias X e U, obtido considerando dois amostras dependentes. Com base neles, N pares da forma (x eu, y eu), onde X eu, sim, eu - os resultados da medição dupla da mesma propriedade para o mesmo objeto. Na pesquisa pedagógica, os objetos de estudo podem ser alunos, professores e gestores escolares. Ao mesmo tempo x eu, sim, eu podem ser, por exemplo, pontos atribuídos por um professor por realizar duas vezes o mesmo trabalho ou um trabalho diferente pelo mesmo grupo de alunos antes e depois de utilizar algum meio pedagógico. Elementos de cada par x eu, sim, eu são comparados entre si em magnitude, e ao par é atribuído um sinal «+»
, se x eu< у
i
, sinal «-»
, se x eu > sim eu E «0»
, se x eu = y eu . Hipótese nula
são formulados da seguinte forma: no estado do imóvel em estudo não há diferenças significativas nas medições primárias e secundárias. Hipótese alternativa: leis de distribuição de quantidades X e V são diferentes, ou seja, os estados da propriedade em estudo são significativamente diferentes na mesma população durante as medições primárias e secundárias desta propriedade. Estatísticas de critério
(T) é definido da seguinte forma: Suponhamos que de N pares (x, y,) havia vários pares em que os valores x eu e y eu são iguais. Tais pares são designados pelo sinal “0” e não são levados em consideração no cálculo do valor de T. Suponhamos que após subtrair do número N o número de pares indicados pelo sinal “0”, apenas n vapor. Entre os restantes n pares, contamos o número de pares indicados pelo sinal “-”, ou seja, pares em que XI<
y i
.
O valor de T e é igual ao número de pares com sinal menos. A hipótese nula é aceita emnível de significância de 0,05 se o valor observado T<
n
-
t a
,
где значение
n
-
t a
determinado a partir de tabelas estatísticas para o critério de sinal do Apêndice 2. Exemplo 4.Os alunos realizaram um teste com o objetivo de testar sua compreensão de um determinado conceito. Quinze alunos receberam então um guia de e-learning concebido para desenvolver o conceito entre alunos com baixas dificuldades de aprendizagem. Depois de estudar o manual, os alunos realizaram novamente o mesmo teste, que foi avaliado em um sistema de cinco pontos. Os resultados da execução do trabalho duas vezes são medidos em uma escala de ordem (escala de cinco pontos). Nessas condições, é possível utilizar o critério do sinal para identificar tendências de mudanças no estado de conhecimento dos alunos após o estudo do manual, desde que todos os pressupostos deste critério sejam atendidos. Anotaremos os resultados da conclusão do trabalho duas vezes (em pontos) por 15 alunos em forma de tabela (ver Tabela 1). Tabela 4. Alunos (N.º) Primeira execução Segunda execução Sinal de diferença de elevação Hipótese sendo testada H0 : O conhecimento dos alunos não melhorou após o estudo do manual. Hipótese alternativa: o conhecimento dos alunos aumentou após o estudo do manual. Vamos calcular o valor da estatística do critério T igual ao número de diferenças positivas nas notas recebidas pelos alunos. De acordo com os dados da Tabela. 4 T=10, n=12. Para determinar os valores críticos das estatísticas do critério n-ta, usamos a tabela. Apêndice 2. Para o nível de significância a = 0,05 em n =12 valor n-ta=9. Portanto, a desigualdade T> n-ta (10>9) é satisfeita. Portanto, de acordo com a regra de decisão, a hipótese nula é rejeitada a um nível de significância de 0,05 e a hipótese alternativa é aceite, o que nos permite concluir que o conhecimento dos alunos melhorou após o estudo independente do manual. Exemplo 5.Supõe-se que o estudo de um curso de matemática contribui para a formação nos alunos de uma das técnicas do pensamento lógico (por exemplo, a técnica da generalização), mesmo que sua formação não seja realizada propositalmente. Para testar essa suposição, o seguinte experimento foi realizado. Alunos VII aula, foram propostos 5 problemas, cuja solução se baseou na utilização desta técnica de pensamento. Considerava-se que um aluno dominava esta técnica se desse a resposta correta a 3 ou mais problemas. Foi desenvolvida a seguinte escala de mensuração: 1 ou 2 problemas resolvidos corretamente – pontuação “0”; 3 problemas resolvidos corretamente – pontuação “1”; 4 problemas resolvidos corretamente – pontuação “2”; 5 problemas resolvidos corretamente - pontuação “3”. A obra foi realizada duas vezes: no final de setembro e no final de maio do ano seguinte. Foi escrito por 35 alunos iguais, selecionados aleatoriamente em 7 escolas diferentes. Anotaremos os resultados da execução do trabalho duas vezes em forma de tabela (ver Tabela 5). De acordo com os objetivos do experimento, formulamos a hipótese nula da seguinte forma: H 0 - estudar matemática não contribui para a formação do método de pensamento estudado. Então a hipótese alternativa ficará assim: H 1 - estudar matemática contribui para o domínio desse método de pensamento. Tabela 5. De acordo com os dados da Tabela. 5, o valor da estatística T=15 é o número de diferenças com o sinal “+”. Dos 35 pares, 12 possuem sinal “0”; Significa, n = 35-12 = 23. De acordo com a tabela do Apêndice 2 para n =23 e um nível de significância de 0,025, encontramos o valor crítico da estatística de teste igual a 16. Portanto, a desigualdade T é verdadeira Portanto, de acordo com a regra de decisão, temos de concluir que os resultados obtidos não fornecem fundamentos suficientes para rejeitar a hipótese nula, ou seja, não temos fundamentos suficientes para rejeitar a afirmação de que o estudo da matemática em si não contribui ao domínio do método de pensamento do assunto selecionado. O teste χ 2 (qui-quadrado) é usado para comparar as distribuições de objetos em duas populações com base em medições em uma escala de nomes em duas populações. independente amostras. Suponhamos que o estado da propriedade em estudo (por exemplo, o desempenho de uma determinada tarefa) seja medido para cada objeto em uma escala de nomenclatura que possui apenas duas categorias mutuamente exclusivas (por exemplo: feito corretamente - feito incorretamente). Com base nos resultados da medição do estado da propriedade em estudo para objetos em duas amostras, uma tabela 2X2 de quatro células é compilada. (ver Tabela 6). Tabela 6. Nesta tabela SOBRE
Então, com base nos dados da tabela 2X2 (ver Tabela 6), é possível testar a hipótese nula sobre a igualdade das probabilidades dos objetos do primeiro e segundo conjuntos enquadrados na primeira (segunda) categoria da escala de medição de a propriedade que está sendo testada, por exemplo, a hipótese sobre a igualdade das probabilidades de conclusão correta de uma determinada tarefa pelas turmas de controle e experimentais. Ao testar hipóteses nulas, não é necessário que os valores de probabilidade página 1 E página 2 eram conhecidas, pois as hipóteses apenas estabelecem certas relações entre elas (igualdade, mais ou menos). Para testar as hipóteses nulas discutidas acima, de acordo com os dados da tabela 2X2 (ver Tabela 6), calcula-se o valor da estatística do critério T de acordo com a seguinte fórmula geral:
onde n 1, n 2 - volumes de amostra,N =n 1 + n 2- número total de observações. A hipótese está sendo testada H0: p 1 £ p 2- com uma alternativa H 1: p 1 >p 2. Deixar a - nível de significância aceito. Então o valor da estatística T, obtido com base em dados experimentais é comparado com o valor crítico das estatísticas x 1-2
a,que é determinado pela tabela 2s um grau de liberdade (ver Apêndice 2) levando em consideração o valor selecionado a . Se a desigualdade for verdadeira T<
x
1-2
a
, então a hipótese nula é aceita no nível a .Se esta desigualdade não for satisfeita, então não temos motivos suficientes para rejeitar a hipótese nula. Devido ao fato de que a substituição da distribuição exata das estatísticas T distribuição 2s um grau de liberdade fornece uma aproximação bastante boa apenas para amostras grandes; o uso do critério é limitado por certas condições. 1) a soma dos volumes de duas amostras é inferior a 20; 2)pelo menos uma das frequências absolutas na tabela 2X2, compilada com base em dados experimentais, é inferior a 5. Exemplo 6.Foi realizado um experimento com o objetivo de identificar o melhor dos livros didáticos escritos por duas equipes de autores de acordo com os objetivos do ensino de geometria e o conteúdo do programa. IX aula. Para realizar a experiência, foram seleccionados dois distritos por selecção aleatória, sendo a maioria das escolas classificadas como rurais por localização. Os alunos do primeiro distrito (20 turmas) estudaram com o livro nº 1, os alunos do segundo distrito (15 turmas) estudaram com o livro nº 2. Consideremos a metodologia para comparar as respostas dos professores em escolas experimentais em dois distritos a uma das perguntas da pesquisa: “O livro didático como um todo é acessível para leitura independente e ajuda você a aprender materiais que o professor não explicou em aula ( Resposta: sim - não.) A atitude dos professores em relação à propriedade estudada dos livros didáticos é medida por uma escala de nomes, que possui duas categorias: sim, não. Ambas as amostras de professores são aleatórias e independentes. Dividiremos as respostas de 20 professores do primeiro distrito e de 15 professores do segundo distrito em duas categorias e as anotaremos na forma de uma tabela 2X2 (Tabela 5). Tabela 7. Todos os valores na tabela. 7 não é inferior a 5, portanto, de acordo com as condições de utilização do critério c2 As estatísticas dos critérios são calculadas usando a fórmula (9).
De acordo com a tabela do Apêndice 2
para um grau de liberdade ( v = eu ) e nível de significância a =0,05 encontraremos x 1-
um um=T crítico = 3,84. Portanto, a observação da desigualdade T é verdadeira<Т критич
(1,86<3,84). Согласно правилу принятия решений
для критерия
c2 , o resultado obtido não fornece motivos suficientes para rejeitar a hipótese nula, ou seja, os resultados do inquérito aos professores em dois distritos experimentais não fornecem motivos suficientes para rejeitar a suposição de disponibilidade igual de livros didáticos №
1
e 2 para os alunos lerem de forma independente. A utilização do teste qui-quadrado também é possível no caso em que os objetos de duas amostras de duas populações, de acordo com o estado do imóvel em estudo, estão distribuídos em mais de duas categorias. Por exemplo, os alunos das aulas experimentais e de controlo são divididos em quatro categorias de acordo com as notas (em pontos: 2, 3, 4, 5) recebidas pelos alunos pela realização de algum trabalho de teste. Os resultados da medição do estado da propriedade em estudo para objetos em cada amostra são distribuídos em COM categorias. Com base nesses dados, é compilada a tabela 2ХС, na qual existem duas linhas (de acordo com o número de populações consideradas) e COM colunas (de acordo com o número de diferentes categorias de estado do imóvel em estudo, adotadas no estudo). Tabela 8. Com base nos dados da Tabela 8, é possível testar a hipótese nula sobre a igualdade das probabilidades dos objetos do primeiro e do segundo conjuntos caindo em cada um doseu (eu = eu,2, ..., C) categorias, ou seja, verificar o cumprimento de todas as seguintes igualdades: p 11 = p 21,
p 12 = p 22, …, p 1 c = p 2 c. É possível, por exemplo, testar a hipótese sobre a igualdade das probabilidades de obtenção das notas “5”, “4”, “3” e “2” para a realização de determinada tarefa pelos alunos das aulas controle e experimentais. Para testar a hipótese nula usando o critério c2
Com base nos dados da Tabela 2ХС, o valor das estatísticas do critério é calculado T de acordo com a seguinte fórmula:
Onde nº 1 E nº 2- tamanhos de amostra. Significado T, obtido com base em dados experimentais é comparado com o valor crítico x 1-
a,que é determinado pela tabela c 2 c k =Com -1 grau de liberdade levando em consideração o nível de significância selecionado a . Quando a desigualdade se mantém T> x 1-
um uma hipótese nula é rejeitada em A e a hipótese alternativa é aceita. Isso significa que a distribuição de objetos em COM as categorias de acordo com o estado do imóvel em estudo são diferentes nas duas populações consideradas. Exemplo 7. Consideremos uma metodologia de comparação dos resultados de trabalhos escritos que testaram o domínio de uma das seções do curso por alunos da primeira e segunda regiões. Utilizando um método de seleção aleatória, foi elaborada uma amostra de 50 pessoas entre os alunos do primeiro distrito que escreveram o trabalho, e uma amostra de 50 pessoas entre os alunos do segundo distrito. De acordo com critérios especialmente desenvolvidos para avaliação do desempenho do trabalho, cada aluno poderia se enquadrar em uma das quatro categorias: ruim, medíocre, bom, excelente. Utilizamos os resultados do trabalho realizado por duas amostras de alunos para testar a hipótese de que o livro didático nº 1 promove melhor domínio da seção testada do curso, ou seja, os alunos do primeiro distrito experimental receberão, em média, notas mais altas do que alunos do segundo distrito. Escreveremos os resultados dos trabalhos realizados pelos alunos de ambas as amostras na forma de uma tabela 2X4 (Tabela. 9
).
Tabela 9. De acordo com os termos de uso do critério c2 As estatísticas dos critérios são calculadas utilizando a fórmula ajustada (10).
De acordo com as condições de aplicação do teste qui-quadrado bilateral conforme tabela do Anexo 2
para um grau de liberdade ( k Grabar M.I., Krasnyanskaya K.A. Aplicação da estatística matemática na pesquisa educacional. Métodos não paramétricos. M., “Pedagogia”, 1977, p. Grabar M.I., Krasnyanskaya K.A. Aplicação da estatística matemática na pesquisa educacional. Métodos não paramétricos. M., “Pedagogia”, 1977, p.
![]()
![]()
![]()
b) caso de amostras relacionadas (pareadas)
 (6)
(6)


6.1.3 F - Teste de Fisher
![]()
6.2 Testes não paramétricos
6.2.1 Critério de sinalização ( Teste G)

6.2.2 Teste χ2 (qui-quadrado)

 (9)
(9)


 (10)
(10)
![]()
O método discutido acima funciona bem se o sinal qualitativo que nos interessa assumir dois valores (há trombose - não, o marciano é verde - rosa). Além disso, como o método é análogo direto ao teste de Student, o número de amostras comparadas também deve ser igual a duas.
É claro que tanto o número de valores de atributos quanto o número de amostras podem ser superiores a dois. Para analisar tais casos, é necessário outro método semelhante à análise de variância. Na aparência, este método, que apresentaremos agora, é muito diferente do critério z, mas na verdade há muito em comum entre eles.
Para não ir muito longe como exemplo, vamos começar com o problema da trombose de shunt que acabamos de discutir. Agora consideraremos não a proporção, mas o número de pacientes com trombose. Vamos inserir os resultados do teste na tabela (Tabela 5.1). Para cada grupo indicaremos o número de pacientes com trombose e sem trombose. Temos dois sinais: o medicamento (aspirina-placebo) e a trombose (sim-não); a tabela mostra todas as suas combinações possíveis, portanto tal tabela é chamada de tabela de contingência. Neste caso, o tamanho da mesa é 2x2.
Vejamos as células localizadas em uma diagonal que vai do canto superior esquerdo ao canto inferior direito. Os números neles são visivelmente maiores do que os números em outras células da tabela. Isto sugere uma associação entre o uso de aspirina e o risco de trombose.
Agora vamos dar uma olhada na tabela. 5.2. Esta é uma tabela dos números esperados que obteríamos se a aspirina não tivesse efeito sobre o risco de trombose. Discutiremos como calcular os números esperados um pouco mais abaixo, mas por enquanto vamos prestar atenção aos recursos externos da tabela. Além dos números fracionários um pouco assustadores nas células, você pode notar outra diferença na tabela. 5.1 são os dados resumidos para grupos na coluna da direita e para trombose na linha inferior. No canto inferior direito está o número total de pacientes no ensaio. Sobre-
Observe que embora os números nas células da Fig. 5.1 e 5.2 são diferentes, as somas nas linhas e colunas são iguais.
Como você calcula os números esperados? 25 pessoas receberam placebo, aspirina - 19. Trombose de shunt ocorreu em 24 dos 44 examinados, ou seja, em 54,55% dos casos não ocorreu - em 20 dos 44, ou seja, em 45,45% dos casos. Aceitemos a hipótese nula de que a aspirina não afeta o risco de trombose. Em seguida, a trombose deve ser observada com igual frequência de 54,55% nos grupos placebo e aspirina. Calculando quanto é 54,55% de 25 e 19, obtemos 13,64 e 10,36, respectivamente. Estes são os números esperados de pacientes com trombose nos grupos placebo e aspirina. Da mesma forma, pode-se obter o número esperado de pacientes sem trombose no grupo placebo - 45,45% de 25, ou seja, 11,36 no grupo aspirina - 45,45% de 19, ou seja, 8,64; Observe que os números esperados são calculados com a segunda casa decimal - essa precisão será necessária em cálculos posteriores.
Vamos comparar a tabela. 5.1 e 5.2. Os números nas células variam bastante. Portanto, o quadro real difere daquele que teria sido observado se a aspirina não tivesse efeito sobre o risco de trombose. Agora resta construir um critério que caracterize essas diferenças com um número, e então encontrar seu valor crítico - ou seja, fazer o mesmo que no caso dos critérios F, t ou z.
No entanto, primeiro lembremo-nos de outro princípio que já nos é familiar -
O trabalho de Mer - Conahan comparando halotano e morfina, nomeadamente a parte onde foi comparada a mortalidade operatória. Os dados correspondentes são fornecidos na tabela. 5.3. A forma da tabela é a mesma da tabela. 5.1. Por sua vez, mesa 5.4 semelhante à tabela. 5.2 contém números esperados, ou seja, números calculados sob a suposição de que a letalidade é independente do agente anestésico. Dos 128 operados, 110 permaneceram vivos, ou seja, 85,94%. Se a escolha da anestesia não tivesse efeito na mortalidade, então em ambos os grupos a proporção de sobreviventes seria a mesma e o número de sobreviventes seria no grupo halotano - 85,94% de 61, ou seja, 52,42 no grupo morfina - 85,94 % de 67, isso é 57,58. O número esperado de mortes pode ser obtido da mesma forma. Vamos comparar as tabelas 5.3 e 5.4. Ao contrário do exemplo anterior, as diferenças entre os valores esperados e observados são muito pequenas. Como descobrimos anteriormente, não há diferença na mortalidade. Parece que estamos no caminho certo.
Critérios x2 para uma tabela 2x2
O teste x2 (leia-se “qui-quadrado”) não requer quaisquer suposições sobre os parâmetros da população da qual as amostras são extraídas - este é o primeiro dos testes não paramétricos com os quais somos apresentados. Vamos começar a construí-lo. Primeiro, como sempre, o critério deve dar um número,
que serviria como medida da diferença entre os dados observados e os esperados, ou seja, neste caso, a diferença entre a tabela de números observados e esperados. Em segundo lugar, o critério deve ter em conta que uma diferença de, digamos, um paciente é mais significativa quando o número esperado é pequeno do que quando o número esperado é grande.
Vamos definir o critério x2 da seguinte forma:
onde O é o número observado em uma célula da tabela de contingência, E é o número esperado na mesma célula. A soma é realizada em todas as células da tabela. Como pode ser visto na fórmula, quanto maior a diferença entre os números observados e esperados, maior será a contribuição da célula para o valor% 2. Neste caso, as células com um número esperado pequeno dão uma contribuição maior. Assim, o critério satisfaz ambos os requisitos - em primeiro lugar, mede as diferenças e, em segundo lugar, tem em conta a sua magnitude em relação aos números esperados.
Apliquemos o critério x2 aos dados sobre trombose de shunt. Na tabela 5.1 mostra os números observados e tabela. 5.2 - esperado.
![]()
O valor z obtido a partir dos mesmos dados também foi semelhante. Pode-se mostrar que para tabelas de contingência de tamanho 2x2 a igualdade X2 = z2 é válida.
O valor crítico% 2 pode ser encontrado de uma forma que conhecemos bem. Na Fig. A Figura 5.7 mostra a distribuição dos valores possíveis de X2 para tabelas de contingência de tamanho 2x2 para o caso em que não há conexão entre as características em estudo. O valor de X2 ultrapassa 3,84 apenas em 5% dos casos. Assim, 3,84 é o valor crítico para o nível de significância de 5%. No exemplo da trombose de shunt obtivemos um valor de 7,10, portanto rejeitamos a hipótese de que não há associação entre o uso de aspirina e coágulos sanguíneos. Pelo contrário, os dados da Tabela. 5.3 concordam com a hipótese de que o halotano e a morfina têm o mesmo efeito na mortalidade pós-operatória.
É claro que, como todos os critérios de significância, x2 fornece uma avaliação probabilística da veracidade de uma hipótese específica. Na verdade, a aspirina pode não ter efeito no risco de trombose. Na verdade, o halotano e a morfina podem ter efeitos diferentes na mortalidade operatória. Mas, como o critério mostrou, ambos são improváveis.
A aplicação do critério x2 é legal se o número esperado em qualquer uma das células for maior ou igual a 5. Esta condição é semelhante à condição de aplicabilidade do critério z.
O valor crítico %2 depende do tamanho da tabela de contingência, ou seja, do número de tratamentos comparados (linhas da tabela) e do número de resultados possíveis (colunas da tabela). O tamanho da tabela é expresso pelo número de graus de liberdade v:
V = (r - 1)(s - 1),
onde r é o número de linhas e c é o número de colunas. Para tabelas de tamanho 2x2 temos v = (2 - l)(2 - l) = l. Os valores críticos de %2 para diferentes v são dados na tabela. 5.7.
A fórmula dada anteriormente para x2 no caso de uma tabela 2x2 (ou seja, com 1 grau de liberdade) fornece valores ligeiramente superestimados (situação semelhante ocorreu com o critério z). Isso ocorre porque a distribuição teórica de x2 é contínua, enquanto o conjunto de valores calculados de x2 é discreto. Na prática, isso resultará na rejeição da hipótese nula com muita frequência. Para compensar este efeito, a correção de Yeats é introduzida na fórmula: (1 O - E - -
Observe que a correção de Yeats só se aplica quando v = 1, ou seja, para tabelas 2x2.
Vamos aplicar a correção de Yeats para estudar a relação entre tomar aspirina e trombose de shunt (Tabelas 5.1 e 5.2):
Como você se lembra, sem a correção de Yates, o valor %2 era 7,10. O valor %2 corrigido foi inferior a 6,635, o valor crítico para o nível de significância de 1%, mas ainda excedeu 5,024, o valor crítico para o nível de significância de 2,5%.
Critério X2 para uma tabela de contingência arbitrária
Agora considere o caso em que a tabela de contingência tem mais linhas ou colunas do que duas. Observe que o teste z não é aplicável nesses casos.
Polegada. 3 mostramos que correr reduz o número de menstruações*. Essas mudanças levam você a consultar um médico? Na tabela A Tabela 5.5 mostra os resultados de uma pesquisa com participantes do estudo. Esses dados apoiam a hipótese de que correr não afeta a probabilidade de consultar um médico por irregularidade menstrual?
Das 165 mulheres examinadas, 69 (ou seja, 42%) consultaram um médico, as restantes 96 (ou seja, 58%) não consultaram um médico. Se
* Ao mesmo tempo, para simplificar os cálculos, assumimos que os tamanhos de todos os três grupos - controle, atletas femininas e atletas femininas - eram iguais. Agora usaremos dados reais.
correr não afeta a probabilidade de consultar um médico, então, em cada um dos grupos, 42% das mulheres deveriam ter consultado um médico. Na tabela 5.6 mostra os valores esperados correspondentes. Os dados reais são muito diferentes deles?
Para responder a esta pergunta, vamos calcular %2:
(14 - 22,58)2 (40 - 31,42)2 (9 - 9,62)2
22,58 31,42 9,62
(14 - 13,38)2 (46 - 36,80)2 (42 - 51,20)2
13,38 36,80 51,20
O número de linhas na tabela de contingência é três, as colunas são duas, então o número de graus de liberdade é v = (3 - 1)(2 - 1) = 2. Se a hipótese sobre a ausência de diferenças intergrupos estiver correta , então, como pode ser visto na tabela. 5.7 o valor de %2 excederá 9,21 em não mais que 1% dos casos. O valor resultante é maior. Assim, no nível de significância de 0,01, podemos rejeitar a hipótese de que não há ligação entre corrida e visitas ao médico sobre menstruação. No entanto, tendo descoberto que existe uma ligação, não poderemos, no entanto, indicar quais (quais) grupos diferem dos restantes.
Então, nos familiarizamos com o critério %2. Aqui está o procedimento para usá-lo.
Construa uma tabela de contingência com base nos dados disponíveis.
Conte o número de objetos em cada linha e em cada coluna e descubra qual proporção do número total de objetos esses valores constituem.
Conhecendo essas parcelas, calcule os números esperados com até duas casas decimais - o número de objetos que
cairia em todas as células da tabela se não houvesse conexão entre linhas e colunas
Encontre o valor que caracteriza as diferenças entre os valores observados e esperados. Se a tabela de contingência for 2x2, aplique a correção de Yeats
Calcule o número de graus de liberdade, selecione o nível de significância e conforme tabela. 5.7, determine o valor crítico %2. Compare com o que você tem para sua mesa.
Como você lembra, para tabelas de contingência de tamanho 2x2, o critério x2 só é aplicável quando todos os números esperados são maiores que 5. E quanto a tabelas de tamanhos maiores? Neste caso, o critério %2 é aplicável se todos os números esperados não forem inferiores a 1 e a proporção de células com números esperados inferiores a 5 não exceder 20%. Se estas condições não forem satisfeitas, os critérios x2 podem dar resultados falsos. Neste caso, é possível recolher dados adicionais, mas nem sempre é viável. Existe uma maneira mais fácil - combinar várias linhas ou colunas. Abaixo mostraremos como fazer isso.
Conversão de tabelas de contingência
Na secção anterior, estabelecemos a existência de uma ligação entre a corrida e as visitas ao médico sobre a menstruação, ou, o que dá no mesmo, a existência de diferenças entre os grupos na frequência das visitas ao médico. No entanto, não foi possível determinar quais grupos diferiam entre si e quais não. Encontramos uma situação semelhante na análise de variância. Ao comparar vários grupos, a análise de variância permite detectar o próprio fato da existência de diferenças, mas não indica quais grupos se destacam. Este último pode ser feito usando procedimentos de comparação múltipla, que discutimos no Capítulo. 4. Algo semelhante pode ser feito com tabelas de contingência.
Olhando para a mesa. 5.5, pode-se supor que as atletas e desportistas do sexo feminino consultaram um médico com mais frequência do que as mulheres do grupo de controle. A diferença entre atletas femininas e atletas femininas parece insignificante.
Vamos testar a hipótese de que atletas e atletas femininas
| V | 0,50 | 0,25 | 0,10 | 0,05 | 0,025 | 0,01 | 0,005 | 0,001 |
| 41 | 40,335 | 46,692 | 52,949 | 56,942 | 60,561 | 64,950 | 68,053 | 74,745 |
| 42 | 41,335 | 47,766 | 54,090 | 58,124 | 61,777 | 66,206 | 69,336 | 76,084 |
| 43 | 42,335 | 48,840 | 55,230 | 59,304 | 62,990 | 67,459 | 70,616 | 77,419 |
| 44 | 43,335 | 49,913 | 56,369 | 60,481 | 64,201 | 68,710 | 71,893 | 78,750 |
| 45 | 44,335 | 50,985 | 57,505 | 61,656 | 65,410 | 69,957 | 73,166 | 80,077 |
| 46 | 45,335 | 52,056 | 58,641 | 62,830 | 66,617 | 71,201 | 74,437 | 81,400 |
| 47 | 46,335 | 53,127 | 59,774 | 64,001 | 67,821 | 72,443 | 75,704 | 82,720 |
| 48 | 47,335 | 54,196 | 60,907 | 65,171 | 69,023 | 73,683 | 76,969 | 84,037 |
| 49 | 48,335 | 55,265 | 62,038 | 66,339 | 70,222 | 74,919 | 78,231 | 85,351 |
| 50 | 49,335 | 56,334 | 63,167 | 67,505 | 71,420 | 76,154 | 79,490 | 86,661 |
| Nível de significância |
| JH Zar, Análise Bioestatística, 2ª ed, Prentice-Hall, Englewood Cliffs, NJ, 1984. |
Eles visitam o médico com a mesma frequência. Para fazer isso, selecione uma subtabela da tabela original contendo dados desses dois grupos. Na tabela 5.8 mostra os números observados e esperados; eles estão bem próximos.
Teste estatístico
A regra pela qual a hipótese I 0 é rejeitada ou aceita é chamada critério estatístico. O nome do critério, via de regra, contém uma letra que denota uma característica especialmente compilada da cláusula 2 do algoritmo de teste de hipótese estatística (ver cláusula 4.1), calculada no critério. Nas condições deste algoritmo, o critério seria chamado "V-critério".
Ao testar hipóteses estatísticas, dois tipos de erros são possíveis:
- - Erro tipo I(você pode rejeitar a hipótese I 0 quando ela for realmente verdadeira);
- - Erro tipo II(você pode aceitar a hipótese I 0 quando na verdade ela não é verdadeira).
Probabilidade A cometer um erro do primeiro tipo é chamado nível de significância do critério.
Se por R denotam a probabilidade de cometer um segundo erro de tipo, então (l - R) - a probabilidade de não cometer um erro do segundo tipo, que é chamado poder do critério.
Teste de adequação de Pearson x 2
Existem vários tipos de hipóteses estatísticas:
- - sobre a lei da distribuição;
- - homogeneidade das amostras;
- - valores numéricos dos parâmetros de distribuição, etc.
Consideraremos a hipótese sobre a lei de distribuição usando o exemplo do teste de ajuste x 2 de Pearson.
Critério de acordoé chamado de critério estatístico para testar a hipótese nula sobre a lei assumida de uma distribuição desconhecida.
O teste de adequação de Pearson é baseado em uma comparação de frequências empíricas (observadas) e teóricas de observações calculadas sob a suposição de uma determinada lei de distribuição. A hipótese nº 0 aqui é formulada da seguinte forma: de acordo com a característica que está sendo estudada, a população tem distribuição normal.
Algoritmo de teste de hipótese estatística nº 0 para critério x 1 Pearson:
- 1) levantamos a hipótese I 0 - de acordo com a característica em estudo, a população geral está distribuída normalmente;
- 2) calcular a média amostral e o desvio padrão amostral Ó V;
3) de acordo com a amostra de volume disponível P calculamos uma característica especialmente compilada,
onde: i, são frequências empíricas,  - frequências teóricas,
- frequências teóricas,
P - tamanho da amostra,
h- o tamanho do intervalo (a diferença entre duas opções adjacentes),
Valores normalizados da característica observada,
![]() - função de tabela. Também frequências teóricas
- função de tabela. Também frequências teóricas
pode ser calculado usando a função DIST.NORMID padrão do MS Excel usando a fórmula;
4) usando a distribuição amostral, determinamos o valor crítico de uma característica especialmente compilada xl P
5) quando a hipótese nº 0 é rejeitada, quando a hipótese nº 0 é aceita.
Exemplo. Vamos considerar o sinal X- o valor dos indicadores de testagem para presidiários de uma das colônias correcionais para alguma característica psicológica, apresentado na forma de uma série de variação:
A um nível de significância de 0,05, teste a hipótese sobre a distribuição normal da população.
1. Com base na distribuição empírica, uma hipótese pode ser apresentada H 0: de acordo com o critério estudado “o valor do indicador de testagem para uma determinada característica psicológica”, a população em geral
esperado é distribuído normalmente. Hipótese alternativa 1: de acordo com o critério estudado “o valor do indicador de teste para uma determinada característica psicológica”, a população geral de apenados não tem distribuição normal.
2. Vamos calcular as características numéricas da amostra:

|
Intervalos |
x g e |
X) sch |
 |
||||
3. Vamos calcular a característica especialmente compilada j 2 . Para isso, na penúltima coluna da tabela anterior encontramos as frequências teóricas através da fórmula, e na última coluna
Vamos calcular as características % 2. Nós temos x 2 = 0,185.
Para maior clareza, construiremos um polígono da distribuição empírica e uma curva normal baseada em frequências teóricas (Fig. 6).

Arroz. 6.
4. Determine o número de graus de liberdade é: k = 5, t = 2, s = 5-2-1 = 2.
Conforme tabela ou utilizando a função padrão do MS Excel “HI20BR” para o número de graus de liberdade 5 = 2 e o nível de significância uma = 0,05 encontraremos o valor crítico do critério xlP.=5,99. Para nível de significância A= 0,01 valor do critério crítico X%. = 9,2.
5. Valor do critério observado X=0,185 menor que todos os valores encontrados Hk R.-> portanto, a hipótese I 0 é aceita em ambos os níveis de significância. A discrepância entre frequências empíricas e teóricas é insignificante. Portanto, os dados observacionais são consistentes com a hipótese de uma distribuição normal da população. Assim, de acordo com o critério estudado “o valor do indicador de testagem para uma determinada característica psicológica”, a população geral de apenados está distribuída normalmente.
- 1. Koryachko A.V., Kulichenko A.G. Matemática superior e métodos matemáticos em psicologia: guia de aulas práticas para alunos da Faculdade de Psicologia. Riazan, 1994.
- 2. Nasledov A.D. Métodos matemáticos de pesquisa psicológica. Análise e interpretação dos dados: Livro didático, manual. São Petersburgo, 2008.
- 3.Sidorenko E.V. Métodos de processamento matemático em psicologia. São Petersburgo, 2010.
- 4. Soshnikova L.A. e outros. Análise estatística multivariada em economia: livro didático, manual para universidades. M., 1999.
- 5. Sukhodolsky E.V. Métodos matemáticos em psicologia. Carcóvia, 2004.
- 6. Shmoilova R.A., Minashkin V.E., Sadovnikova N.A. Workshop de teoria da estatística: livro didático, manual. M., 2009.
- Gmurman V.E. Teoria da Probabilidade e Estatística Matemática. Página 465.
O teste χ 2 de Pearson é um método não paramétrico que nos permite avaliar a significância das diferenças entre o número real (revelado) de resultados ou características qualitativas da amostra que se enquadram em cada categoria, e o número teórico que pode ser esperado no estudo grupos se a hipótese nula for verdadeira. Simplificando, o método permite avaliar a significância estatística das diferenças entre dois ou mais indicadores relativos (frequências, proporções).
1. História do desenvolvimento do critério χ 2
O teste qui-quadrado para análise de tabelas de contingência foi desenvolvido e proposto em 1900 por um matemático, estatístico, biólogo e filósofo inglês, fundador da estatística matemática e um dos fundadores da biometria Carlos Pearson(1857-1936).
2. Por que é utilizado o teste χ 2 de Pearson?
O teste qui-quadrado pode ser usado na análise Tabelas de contingência contendo informações sobre a frequência dos desfechos dependendo da presença de um fator de risco. Por exemplo, tabela de contingência de quatro campos do seguinte modo:
| Há um resultado (1) | Nenhum resultado (0) | Total | |
| Existe um fator de risco (1) | A | B | A+B |
| Nenhum fator de risco (0) | C | D | C+D |
| Total | A+C | B+D | A+B+C+D |
Como preencher essa tabela de contingência? Vejamos um pequeno exemplo.
Está sendo realizado um estudo sobre o efeito do tabagismo no risco de desenvolver hipertensão arterial. Para tanto, foram selecionados dois grupos de sujeitos - o primeiro incluiu 70 pessoas que fumam pelo menos 1 maço de cigarros diariamente, o segundo incluiu 80 não fumantes da mesma idade. No primeiro grupo, 40 pessoas tinham pressão alta. No segundo, a hipertensão arterial foi observada em 32 pessoas. Assim, a pressão arterial normal no grupo de fumantes foi em 30 pessoas (70 - 40 = 30) e no grupo de não fumantes - em 48 (80 - 32 = 48).
Preenchemos a tabela de contingência de quatro campos com os dados iniciais:
Na tabela de contingência resultante, cada linha corresponde a um grupo específico de sujeitos. As colunas mostram o número de pessoas com hipertensão arterial ou pressão arterial normal.
A tarefa que se coloca ao investigador é: existem diferenças estatisticamente significativas entre a frequência de pessoas com pressão arterial entre fumadores e não fumadores? Esta questão pode ser respondida calculando o teste qui-quadrado de Pearson e comparando o valor resultante com o valor crítico.
3. Condições e limitações para utilização do teste qui-quadrado de Pearson
- Indicadores comparáveis devem ser medidos em escala nominal(por exemplo, o sexo do paciente é masculino ou feminino) ou em ordinal(por exemplo, o grau de hipertensão arterial, assumindo valores de 0 a 3).
- Este método permite analisar não apenas tabelas de quatro campos, quando tanto o fator quanto o resultado são variáveis binárias, ou seja, possuem apenas dois valores possíveis (por exemplo, sexo masculino ou feminino, presença ou ausência de um determinada doença na anamnese...). O teste qui-quadrado de Pearson também pode ser utilizado no caso de análise de tabelas multicampos, quando um fator e (ou) resultado assume três ou mais valores.
- Os grupos a serem comparados devem ser independentes, ou seja, o teste do qui-quadrado não deve ser utilizado na comparação das observações antes e depois. Teste de McNemar(ao comparar duas populações relacionadas) ou calculado Teste Q de Cochran(em caso de comparação de três ou mais grupos).
- Ao analisar tabelas de quatro campos valores esperados em cada célula deve haver pelo menos 10. Se em pelo menos uma célula o fenômeno esperado assumir um valor de 5 a 9, deve-se calcular o teste do qui-quadrado com a alteração de Yates. Se em pelo menos uma célula o fenômeno esperado for menor que 5, então a análise deverá utilizar Teste exato de Fisher.
- Ao analisar tabelas multicampos, o número esperado de observações não deve ser inferior a 5 em mais de 20% das células.
4. Como calcular o teste qui-quadrado de Pearson?
Para calcular o teste qui-quadrado você precisa:

Este algoritmo é aplicável para tabelas de quatro campos e de vários campos.
5. Como interpretar o valor do teste qui-quadrado de Pearson?
Se o valor obtido do critério χ 2 for superior ao valor crítico, concluímos que existe relação estatística entre o fator de risco estudado e o desfecho no nível de significância adequado.
6. Exemplo de cálculo do teste qui-quadrado de Pearson
Determinemos a significância estatística da influência do fator tabagismo na incidência de hipertensão arterial usando a tabela discutida acima:
- Calculamos os valores esperados para cada célula:
- Encontre o valor do teste qui-quadrado de Pearson:
χ 2 = (40-33,6) 2 /33,6 + (30-36,4) 2 /36,4 + (32-38,4) 2 /38,4 + (48-41,6) 2 /41,6 = 4,396.
- O número de graus de liberdade f = (2-1)*(2-1) = 1. Utilizando a tabela, encontramos o valor crítico do teste qui-quadrado de Pearson, que no nível de significância p=0,05 e o número de graus de liberdade 1 é 3,841.
- Comparamos o valor obtido do teste qui-quadrado com o valor crítico: 4,396 > 3,841, portanto, a dependência da incidência de hipertensão arterial com a presença de tabagismo é estatisticamente significativa. O nível de significância desta relação corresponde a p<0.05.
Considere a aplicação emEMEXCELTeste qui-quadrado de Pearson para testar hipóteses simples.
Depois de obter dados experimentais (ou seja, quando há alguma amostra) geralmente é feita a escolha da lei de distribuição que melhor descreve a variável aleatória representada por um determinado amostragem. A verificação de quão bem os dados experimentais são descritos pela lei de distribuição teórica selecionada é realizada usando critérios de acordo. Hipótese nula, geralmente existe uma hipótese sobre a igualdade da distribuição de uma variável aleatória a alguma lei teórica.
Vejamos primeiro o aplicativo Teste de ajuste de Pearson X 2 (qui-quadrado) em relação a hipóteses simples (os parâmetros da distribuição teórica são considerados conhecidos). Então - , quando apenas a forma da distribuição é especificada, e os parâmetros desta distribuição e o valor Estatisticas X 2 são avaliados/calculados com base no mesmo amostras.
Observação: Na literatura de língua inglesa, o procedimento de inscrição Teste de adequação de Pearson X 2 tem um nome O teste de qualidade de ajuste do qui-quadrado.
Vamos relembrar o procedimento para testar hipóteses:
- baseado amostras o valor é calculado Estatisticas, que corresponde ao tipo de hipótese que está sendo testada. Por exemplo, para usado t-Estatisticas(se não for conhecido);
- sujeito à verdade hipótese nula, a distribuição deste Estatisticasé conhecido e pode ser usado para calcular probabilidades (por exemplo, para t-Estatisticas Esse );
- calculado com base em amostras significado Estatisticas comparado com o valor crítico para um determinado valor ();
- hipótese nula rejeitar se valor Estatisticas maior que o crítico (ou se a probabilidade de obter este valor Estatisticas() menos nível de significância, que é uma abordagem equivalente).
Vamos realizar testando hipóteses para diversas distribuições.
Caso discreto
Suponha que duas pessoas estejam jogando dados. Cada jogador tem seu próprio conjunto de dados. Os jogadores se revezam no lançamento de 3 dados de uma vez. Cada rodada é vencida por aquele que tirar mais seis de cada vez. Os resultados são registrados. Um dos jogadores, após 100 rodadas, suspeitou que os dados do seu oponente eram assimétricos, pois ele frequentemente ganha (ele frequentemente lança seis). Ele decidiu analisar a probabilidade de tal número de resultados inimigos.
Observação: Porque Existem 3 cubos, então você pode rolar 0 de cada vez; 1; 2 ou 3 seis, ou seja uma variável aleatória pode assumir 4 valores.
Da teoria das probabilidades sabemos que se os dados forem simétricos, então a probabilidade de obter seis obedece. Portanto, após 100 rodadas, as frequências de seis podem ser calculadas usando a fórmula
=BINOM.DIST(A7,3,1/6,FALSO)*100
A fórmula assume que na célula A7 contém o número correspondente de seis lançados em uma rodada.
Observação: Os cálculos são dados em arquivo de exemplo na planilha discreta.
Para comparação observado(Observado) e frequências teóricas(Esperado) conveniente de usar.

Se as frequências observadas se desviarem significativamente da distribuição teórica, hipótese nula sobre a distribuição de uma variável aleatória de acordo com uma lei teórica deve ser rejeitada. Ou seja, se os dados do oponente forem assimétricos, então as frequências observadas serão “significativamente diferentes” das distribuição binomial.
No nosso caso, à primeira vista, as frequências são bastante próximas e sem cálculos é difícil tirar uma conclusão inequívoca. Aplicável Teste de adequação de Pearson X 2, de modo que em vez da afirmação subjetiva “substancialmente diferente”, que pode ser feita com base na comparação histogramas, use uma afirmação matematicamente correta.
Usamos o fato de que devido a lei dos grandes números frequência observada (Observado) com o aumento do volume amostras n tende à probabilidade correspondente à lei teórica (no nosso caso, lei binomial). No nosso caso, o tamanho da amostra n é 100.
Vamos apresentar teste Estatisticas, que denotamos por X 2:

onde O l é a frequência observada de eventos em que a variável aleatória assumiu certos valores aceitáveis, E l é a frequência teórica correspondente (esperada). L é o número de valores que uma variável aleatória pode assumir (no nosso caso é 4).
Como pode ser visto na fórmula, isso Estatisticasé uma medida da proximidade das frequências observadas com as teóricas, ou seja, pode ser usado para estimar as “distâncias” entre essas frequências. Se a soma dessas “distâncias” for “muito grande”, então essas frequências serão “significativamente diferentes”. É claro que se o nosso cubo for simétrico (ou seja, aplicável lei binomial), então a probabilidade de que a soma das “distâncias” seja “muito grande” será pequena. Para calcular esta probabilidade precisamos conhecer a distribuição Estatisticas X 2 ( Estatisticas X 2 calculado com base em dados aleatórios amostras, portanto é uma variável aleatória e, portanto, tem seu próprio distribuição de probabilidade).
Do análogo multidimensional Teorema integral de Moivre-Laplace sabe-se que para n->∞ nossa variável aleatória X 2 é assintoticamente com L - 1 graus de liberdade.
Então, se o valor calculado Estatisticas X 2 (a soma das “distâncias” entre frequências) será maior que um determinado valor limite, então teremos motivos para rejeitar hipótese nula. O mesmo que verificar hipóteses paramétricas, o valor limite é definido através nível de significância. Se a probabilidade de a estatística X 2 assumir um valor menor ou igual ao calculado ( p-significado), será menor nível de significância, Que hipótese nula pode ser rejeitado.
No nosso caso, o valor estatístico é 22,757. A probabilidade de a estatística X2 assumir um valor maior ou igual a 22,757 é muito pequena (0,000045) e pode ser calculada usando as fórmulas
=CHI2.DIST.PH(22.757,4-1) ou
=CHI2.TEST(Observado; Esperado)
Observação: A função CHI2.TEST() foi projetada especificamente para testar o relacionamento entre duas variáveis categóricas (consulte).
A probabilidade 0,000045 é significativamente menor que o normal nível de significância 0,05. Portanto, o jogador tem todos os motivos para suspeitar de desonestidade de seu oponente ( hipótese nula sua honestidade é negada).

Ao usar critério X 2é necessário garantir que o volume amostras n era grande o suficiente, caso contrário a aproximação da distribuição não seria válida estatísticas X 2. Geralmente acredita-se que para isso basta que as frequências observadas (Observadas) sejam maiores que 5. Caso contrário, as pequenas frequências são combinadas em uma ou adicionadas a outras frequências, e ao valor combinado é atribuído um total probabilidade e, consequentemente, o número de graus de liberdade é reduzido Distribuições X 2.
Para melhorar a qualidade da aplicação critério X 2(), é necessário reduzir os intervalos de partição (aumentar L e, consequentemente, aumentar o número graus de liberdade), no entanto, isso é evitado pela limitação do número de observações incluídas em cada intervalo (db>5).
Caso contínuo
Teste de adequação de Pearson X 2 também pode ser aplicado no caso de.
Vamos considerar um certo amostra, consistindo em 200 valores. Hipótese nula Afirma que amostra feito de.
Observação: Variáveis aleatórias em arquivo de exemplo na planilha Contínua gerado usando a fórmula =NORM.ST.INV(RAND()). Portanto, novos valores amostras são gerados cada vez que a planilha é recalculada.
Se o conjunto de dados existente é apropriado pode ser avaliado visualmente.

Como pode ser visto no diagrama, os valores da amostra se ajustam muito bem ao longo da linha reta. No entanto, como em para testando hipóteses aplicável Teste de ajuste Pearson X 2.
Para fazer isso, dividimos o intervalo de variação da variável aleatória em intervalos com passo de 0,5. Vamos calcular as frequências observadas e teóricas. Calculamos as frequências observadas utilizando a função FREQUENCY(), e as teóricas utilizando a função NORM.ST.DIST().
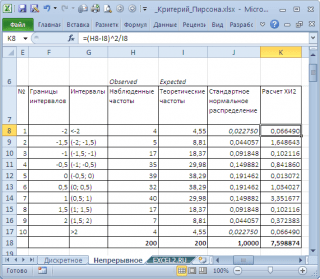
Observação: O mesmo que para caso discreto, é necessário garantir que amostra foi bastante grande e o intervalo incluiu >5 valores.
Vamos calcular a estatística X2 e compará-la com o valor crítico para um determinado nível de significância(0,05). Porque dividimos o intervalo de mudança de uma variável aleatória em 10 intervalos, então o número de graus de liberdade é 9. O valor crítico pode ser calculado usando a fórmula
=CHI2.OBR.PH(0,05;9) ou
=CHI2.OBR(1-0,05;9)
O gráfico acima mostra que o valor estatístico é 8,19, o que é significativamente maior valor crítico – hipótese nula não é rejeitado.
Abaixo é onde amostra assumiu um significado improvável e baseado em critério Consentimento de Pearson X 2 a hipótese nula foi rejeitada (mesmo que os valores aleatórios tenham sido gerados usando a fórmula =NORM.ST.INV(RAND()), fornecendo amostra de distribuição normal padrão).

Hipótese nula rejeitada, embora visualmente os dados estejam localizados bastante próximos de uma linha reta.
Tomemos também como exemplo amostra de você (-3; 3). Neste caso, mesmo a partir do gráfico, é óbvio que hipótese nula deveria ser rejeitado.

Critério Consentimento de Pearson X 2 também confirma que hipótese nula deveria ser rejeitado.



 Banimento oculto de conta no Instagram")





