2 criterios. P.2
Clase 6 Análisis de dos muestras
6.1 Criterios paramétricos. una
6.1.2 Prueba del estudiante ( prueba t) 2
6.1.3 F es la prueba de Fisher. 6
6.2 Pruebas no paramétricas. 7
6.2.1 Criterio de signo ( criterio G) 7
La siguiente tarea del análisis estadístico, que se resuelve después de determinar las características principales (de la muestra) y analizar una muestra, es el análisis conjunto de varias muestras. La pregunta más importante que surge cuando se analizan dos muestras es si hay diferencias entre las muestras. Por lo general, esto se hace contrastando hipótesis estadísticas sobre la pertenencia de ambas muestras a la misma población general o sobre la igualdad de las medias.
Si se nos da el tipo de distribución o función de distribución de la muestra, entonces en este caso el problema de estimar las diferencias entre dos grupos de observaciones independientes se puede resolver usando paramétrico criterios estadísticas: ya sea prueba t de Student ( t ), si la comparación de muestras se basa en valores medios ( X e Y), o utilizando el criterio de Fisher ( F ) si las muestras se comparan por sus varianzas.
El uso de criterios estadísticos paramétricos sin comprobar previamente el tipo de distribución puede dar lugar a ciertos errores.mientras se prueba una hipótesis de trabajo.
Para superar estas dificultades en la práctica de la investigación pedagógica, se debe utilizar no paramétrico criterios Estadísticas , como la prueba de los signos, la prueba de Wilcoxon para dos muestras, la prueba de Van der Waerden, la prueba de Spearman, cuya elección, aunque no requiere un gran número de miembros de la muestra y el conocimiento del tipo de distribución, todavía depende en una serie de condiciones.
Pruebas de estadísticas no paramétricas - están libres del supuesto sobre la ley de distribución de muestras y se basan en el supuesto de la independencia de las observaciones.
6.1 Criterios paramétricos
al grupo criterios paramétricos metodos de estadistica matematica incluye métodos para calcular estadísticas descriptivas, construir gráficos para la normalidad de distribución, probar hipótesis sobre la pertenencia de dos muestras a la misma población. Estos métodos se basan en la suposición de que la distribución de muestras obedece a la ley de distribución normal (gaussiana). Entre los criterios paramétricos de la estadística, consideraremos el criterio de Student y Fisher.
6.1.1 Métodos para analizar la normalidad de la muestra
Para determinar si estamos ante una distribución normal, podemos aplicar los siguientes métodos:
1) dentro de los ejes, puede dibujar un polígono de frecuencia (función de distribución empírica) y curva de distribución normal basado en datos de investigación. Al examinar las formas de la curva de distribución normal y el gráfico de la función de distribución empírica, se pueden encontrar aquellos parámetros en los que la última curva difiere de la primera;
2) calculado Mediana Media y moda, y en base a esto, se determina la desviación de la distribución normal. Si la moda, la mediana y la media aritmética no difieren significativamente entre sí, estamos ante una distribución normal. Si la mediana difiere significativamente de la media, estamos ante una muestra asimétrica.
3) la curtosis de la curva de distribución debe ser igual a 0. Las curvas con curtosis positiva son mucho más verticales que la curva de distribución normal. Las curvas con curtosis negativa tienen más pendiente en comparación con una curva de distribución normal;
4) después de determinar el valor promedio de la distribución de frecuencias y la desviación estándar, encuentre los siguientes cuatro intervalos de distribución y compárelos con los datos reales de la serie:
a) - alrededor del 25% de la frecuencia de la población debe pertenecer al intervalo,
b) - alrededor del 50% de la frecuencia de la población debe pertenecer al intervalo,
c) - alrededor del 75% de la frecuencia de la población debe pertenecer al intervalo,
d) - alrededor del 100% de la frecuencia de la población debe pertenecer al intervalo.
6.1.2 Prueba del estudiante ( prueba t)
El criterio te permite encontrar la probabilidad de que ambas medias en la muestra pertenezcan a la misma población. Este criterio se usa con mayor frecuencia para probar la hipótesis: "Las medias de dos muestras pertenecen a la misma población".
Al utilizar el criterio, se pueden distinguir dos casos. En el primer caso, se utiliza para contrastar la hipótesis sobre la igualdad de las medias generales de dos independiente, no relacionado muestras (llamadas dos muestras prueba t). En este caso, hay un grupo de control y un grupo experimental (experimental), la cantidad de sujetos en los grupos puede ser diferente.
En el segundo caso, cuando el mismo grupo de objetos genera material numérico para probar hipótesis sobre las medias, el llamado prueba t pareada. Las muestras se llaman dependiente, relacionado.
a) el caso de muestras independientes
El estadístico de prueba para el caso de muestras independientes no relacionadas es:
donde , son la media aritmética en los grupos experimental y de control,
El error estándar de la diferencia entre las medias aritméticas. Se encuentra a partir de la fórmula:
![]() ,(2)
,(2)
donde n 1 y n 2 los valores de la primera y segunda muestra, respectivamente.
Si n 1 \u003d n 2, entonces el error estándar de la diferencia entre las medias aritméticas se calculará de acuerdo con la fórmula:
 (3)
(3)
donde n es el tamaño de la muestra.
Contar número de grados de libertad se lleva a cabo de acuerdo con la fórmula:
k \u003d norte 1 + norte 2 - 2. (4)
Con la igualdad numérica de las muestras k = 2 n - 2.
A continuación, debe comparar el valor obtenido de t emp con el valor teórico de la distribución t de Student (consulte el apéndice de los libros de texto de estadística). Si la temperatura Considere un ejemplo de uso t -Test de Student para muestras desconectadas y desiguales. Ejemplo 1 . En dos grupos de estudiantes - experimental y de control - se obtuvieron los siguientes resultados en la asignatura (puntuaciones de las pruebas; ver Tabla 1). Tabla 1. Resultados del experimento El primer grupo (experimental) N 1 = 11 personas Segundo grupo (control) N 2 \u003d 9 personas 121413161191315151814 El número total de miembros de la muestra: n 1 =11, n 2 =9. Cálculo de medias aritméticas: X cf =13,636; Y cf = 9.444 Desviación estándar: s x =2,460; s y = 2.186 Usando la fórmula (2), calculamos el error estándar de la diferencia entre medias aritméticas:
Calculamos las estadísticas del criterio:
Comparamos el valor de t obtenido en el experimento con el valor tabular, teniendo en cuenta los grados de libertad, igual por la fórmula (4) al número de sujetos menos dos (18). El valor tabular de t crit es 2,1, asumiendo el riesgo de emitir un juicio erróneo en cinco casos de cien (nivel de significancia = 5% o 0,05). Si el valor empírico de t obtenido en el experimento excede el valor de la tabla, entonces hay razón para aceptar la hipótesis alternativa (H 1) de que los estudiantes del grupo experimental muestran un nivel de conocimiento promedio más alto. En el experimento t=3.981, tabular t=2.10, 3.981>2.10, de donde se sigue la conclusión sobre la ventaja del aprendizaje experimental. Aquí puede haber preguntas
: 1. ¿Qué pasa si el valor de t obtenido en el experimento resulta ser menor que el tabular? Entonces se debe aceptar la hipótesis nula. 2. ¿Se ha demostrado la ventaja del método experimental? No tanto demostrado como demostrado, porque desde el principio se permite el riesgo de equivocarse en cinco casos de cada cien (p = 0,05). Nuestro experimento podría ser uno de estos cinco casos. Pero el 95% de los casos posibles hablan a favor de la hipótesis alternativa, y este es un argumento bastante convincente en la evidencia estadística. 3. ¿Qué pasa si el grupo de control puntúa mejor que el grupo experimental? Intercambiemos, por ejemplo, haciendo la media aritmética del grupo experimental, a - el control:
Esto implica la conclusión de que el nuevo método aún no ha demostrado ser bueno, posiblemente por varias razones. Dado que el valor absoluto es 3.9811>2.1, se acepta la segunda hipótesis alternativa (H 2) sobre la ventaja del método tradicional. En el caso de muestras vinculadas con el mismo número de mediciones en cada una, se puede utilizar una fórmula de prueba t de Student más simple. El cálculo del valor de t se realiza según la fórmula: donde son las diferencias entre los valores correspondientes de la variable X y la variable Y, y d es el promedio de estas diferencias; Sd se calcula utilizando la siguiente fórmula:
Número de grados de libertad k está determinada por la fórmula k=n -1. Considere un ejemplo del uso de la prueba t de Student para muestras conectadas y, obviamente, iguales en número. Si la temperatura Ejemplo 2. Se estudió el nivel de orientación de los estudiantes a los valores artísticos y estéticos. Para activar la formación de esta orientación en el grupo experimental, se realizaron conversatorios, se organizaron exposiciones de dibujos infantiles, se organizaron visitas a museos y galerías de arte, se realizaron encuentros con músicos, artistas, etc. Naturalmente surge la pregunta: ¿qué es la eficacia del trabajo realizado? Para probar la efectividad de este trabajo, se realizó una prueba antes y después del experimento. Por razones metodológicas, la Tabla 2 muestra los resultados de un pequeño número de sujetos. Tabla 2. Resultados del experimento Estudiantes (n=10) Puntos Cálculos auxiliares
antes del inicio del experimento (X)
en el final experimentar (U)
d d2 Ivánov Nóvikov Sidorov Pirogov Agapov Suvórov Ryzhikov Serov hachas Bystrov Promedio 14,8
21,1
Primero, calcularemos según la fórmula:
Luego aplicamos la fórmula (6), obtenemos: Finalmente, se debe aplicar la fórmula (5). Obtenemos:
El número de grados de libertad: k \u003d 10-1 \u003d 9 y según la tabla del Apéndice 1 encontramos t crit \u003d 2.262, experimental t \u003d 6.678, lo que implica la posibilidad de aceptar una hipótesis alternativa (H 1 ) sobre diferencias significativas en las medias aritméticas, es decir, se llega a una conclusión sobre la efectividad del impacto experimental. En términos de hipótesis estadísticas, el resultado se verá así: al nivel del 5%, se rechaza la hipótesis H 0 y se acepta la hipótesis H 1. criterio de pescador le permite comparar los valores de las varianzas muestrales de dos muestras independientes. Para calcular F emp, necesita encontrar la razón de las varianzas de dos muestras, de modo que la varianza más grande esté en el numerador y la más pequeña en el denominador. La fórmula para calcular el criterio de Fisher es la siguiente: donde son las varianzas de la primera y segunda muestra, respectivamente. Dado que, según la condición del criterio, el valor del numerador debe ser mayor o igual que el valor del denominador, el valor de Femp será siempre mayor o igual a uno. El número de grados de libertad también se define simplemente: k 1 \u003d n l - 1 para la primera muestra (es decir, para la muestra cuya varianza es mayor) y k 2 \u003d n 2 - 1 para la segunda muestra. En el Apéndice 1, los valores críticos del criterio de Fisher se encuentran por los valores k 1 (línea superior de la tabla) y k 2 (columna izquierda de la tabla). Si temp >tcrit, entonces se acepta la hipótesis nula, en caso contrario se acepta la alternativa. Ejemplo 3 En los dos terceros grados, diez estudiantes fueron evaluados para el desarrollo mental según la prueba TURMS. Los valores medios obtenidos no difirieron significativamente, sin embargo, el psicólogo está interesado en la pregunta: ¿existen diferencias en el grado de homogeneidad de los indicadores de desarrollo mental entre las clases? Solución. Para el criterio de Fisher, es necesario comparar las varianzas de las puntuaciones de las pruebas en ambas clases. Los resultados de la prueba se presentan en la tabla: Tabla 3 Nº de alumnos Primer grado Segunda clase sumas Promedio 60,6
63,6
Habiendo calculado las varianzas para las variables X e Y, obtenemos: sx2 = 572,83; s y 2 = 174,04 Entonces, según la fórmula (8) para el cálculo según el criterio de F Fisher, encontramos:
Según la tabla del Apéndice 1 para el criterio F con grados de libertad en ambos casos iguales a k = 10 - 1 = 9, encontramos F crit = 3.18 (<3.29), следовательно, в терминах
статистических гипотез можно утверждать,
что Н 0 (гипотеза о сходстве) может быть
отвергнута на уровне 5%, а принимается в этом
случае гипотеза Н 1 . Иc
следователь
может утверждать, что по степени
однородности такого показателя, как
умственное развитие, имеется различие
между выборками из двух классов. Comparando a simple vista (por porcentaje) los resultados antes y después de cualquier exposición, el investigador llega a la conclusión de que si se observan diferencias, entonces hay una diferencia en las muestras comparadas. Tal enfoque es categóricamente inaceptable, ya que es imposible determinar el nivel de confianza en las diferencias de porcentajes. Los porcentajes tomados por sí solos no permiten sacar conclusiones estadísticamente fiables. Para probar la efectividad de cualquier impacto, es necesario identificar una tendencia estadísticamente significativa en el cambio (cambio) de indicadores. Para resolver tales problemas, el investigador puede utilizar una serie de criterios de diferencia, a continuación se considerarán criterios no paramétricos: la prueba de signos y la prueba de chi-cuadrado. El criterio está diseñado para comparar el estado de alguna propiedad de los miembros de dos dependiente
muestras basado en mediciones hechas en una escala no inferior al rango. Hay dos series de observaciones sobre variables aleatorias X e Y obtenido considerando dos muestras dependientes. En base a ellos, N pares de la forma (x i , y i ), donde X yo, y yo - los resultados de una doble medición de la misma propiedad del mismo objeto. En la investigación pedagógica, los estudiantes, los docentes y las administraciones escolares pueden servir como objetos de estudio. al mismo tiempo x yo, y yo pueden ser, por ejemplo, puntos que otorga el docente por la doble ejecución de un mismo o diferente trabajo por parte de un mismo grupo de alumnos antes y después del uso de determinada herramienta pedagógica. Los elementos de cada par x yo, y yo se comparan entre sí en magnitud, y al par se le asigna el signo «+»
si x i< у
i
, señal «-»
si x yo > y yo y «0»
si x yo = y yo . Hipótesis nula
se formulan de la siguiente manera: en el estado del inmueble estudiado no existen diferencias significativas en las medidas primarias y secundarias. Hipótesis alternativa: leyes de distribución de cantidades X e Y son diferentes, es decir, los estados de la propiedad estudiada son significativamente diferentes en el mismo conjunto en las mediciones primarias y secundarias de esta propiedad. Estadísticas de criterio
(T) se define como sigue: supongamos que de N pares (x, y,) hay varios pares en los que los valores x yo y y yo son iguales. Dichos pares se denotan con el signo "0" y no se tienen en cuenta al calcular el valor de T. Supongamos que después de deducir del número N el número de pares indicado por el signo "0", solo hay norte vapor. entre los restantes norte pares, contamos el número de pares indicado por el signo “-”, es decir, pares en los que x yo<
y i
.
El valor de T y es igual al número de pares con signo menos. Se acepta la hipótesis nula ennivel de significancia de 0.05 si el valor observado T<
n
-
t a
,
где значение
n
-
t a
determinado a partir de las tablas estadísticas para el criterio del signo del Anexo 2. Ejemplo 4Los estudiantes tomaron una prueba para probar su comprensión de un determinado concepto. A quince estudiantes se les ofreció una herramienta de aprendizaje electrónico diseñada para desarrollar este concepto en estudiantes con problemas de aprendizaje. Después de estudiar el manual, los estudiantes volvieron a realizar el mismo trabajo de control, que se evaluó en un sistema de cinco puntos. Los resultados de la doble ejecución del trabajo representan medidas en una escala de orden (escala de cinco puntos). En estas condiciones, es posible utilizar el criterio de signo para identificar la tendencia en el cambio del estado de conocimiento de los estudiantes después de estudiar el manual, ya que se cumplen todos los supuestos de este criterio. Los resultados de la doble realización del trabajo (en puntos) por parte de 15 alumnos se registrarán en forma de tabla (ver Tabla 1). Tabla 4 Estudiantes (nº) Primer intento Segunda ejecución Signo de diferencia de elevación Hipótesis a prueba H0 : el estado de conocimiento de los estudiantes no aumentó después de estudiar el manual. Hipótesis alternativa: el estado de conocimiento de los estudiantes aumentó después de estudiar el manual. Calculemos el valor de las estadísticas del criterio T igual al número de diferencias positivas en las calificaciones recibidas por los estudiantes. De acuerdo con los datos de la Tabla. 4 T=10, n=12. Para determinar los valores críticos de los estadísticos del criterio n-ta, utilizamos Table. Aplicaciones 2. Para el nivel de significancia a = 0.05 en norte =12 valor n-ta=9. Por lo tanto, se cumple la desigualdad T> n-ta (10>9). Por tanto, de acuerdo con la regla de decisión, se rechaza la hipótesis nula a un nivel de significancia de 0,05 y se acepta una hipótesis alternativa, lo que permite concluir que el conocimiento de los alumnos ha mejorado tras el autoaprendizaje del manual. Ejemplo 5Se supone que el estudio de un curso de matemáticas contribuye a la formación en los estudiantes de uno de los métodos del pensamiento lógico (por ejemplo, el método de la generalización), incluso si su formación no se lleva a cabo deliberadamente. Para probar esta suposición, se llevó a cabo el siguiente experimento. Estudiantes VII A la clase se le ofrecieron 5 tareas, cuya solución se basa en el uso de este método de pensamiento. Se creía que el estudiante es dueño de esta técnica si da la respuesta correcta a 3 o más tareas. Se desarrolló la siguiente escala de medición: 1 o 2 tareas fueron resueltas correctamente - puntuación "0"; resolvió correctamente 3 tareas - puntuación "1"; resolvió correctamente 4 tareas - puntuación "2"; 5 tareas fueron resueltas correctamente - puntuación "3". La obra se llevó a cabo en dos ocasiones: a finales de septiembre ya finales de mayo del año siguiente. Fue escrito por 35 de los mismos estudiantes, seleccionados al azar de 7 escuelas diferentes. Los resultados de hacer el trabajo dos veces se escribirán en forma de tabla (ver Tabla 5). De acuerdo con los objetivos del experimento, formulamos la hipótesis nula de la siguiente manera: H 0: el estudio de las matemáticas no contribuye a la formación del método de pensamiento estudiado. Entonces la hipótesis alternativa se verá así: H 1 - el estudio de las matemáticas contribuye al dominio de este método de pensamiento. Tabla 5 De acuerdo con los datos de la Tabla. 5, el valor de las estadísticas T=15 - el número de diferencias con el signo "+". De los 35 pares, 12 tienen el signo "0"; medio, n=35-12=23. Según la tabla del Apéndice 2 para norte =23 y un nivel de significancia de 0.025, encontramos el valor crítico del estadístico de prueba igual a 16. Por lo tanto, la desigualdad Т Por lo tanto, de acuerdo con la regla de decisión, tenemos que concluir que los resultados obtenidos no dan motivos suficientes para rechazar la hipótesis nula, es decir, no tenemos motivos suficientes para rechazar la afirmación de que el estudio de las matemáticas en sí mismo no contribuye. dominar la forma de pensar seleccionada. El criterio χ 2 (chi-cuadrado) se usa para comparar las distribuciones de objetos de dos poblaciones con base en medidas en la escala de nombres en dos independiente muestras Suponga que el estado de la propiedad estudiada (por ejemplo, la finalización de una determinada tarea) se mide para cada objeto en una escala de nombres que tiene solo dos categorías mutuamente excluyentes (por ejemplo: hecho correctamente - hecho incorrectamente). De acuerdo con los resultados de medir el estado de la propiedad en estudio en los objetos de dos muestras, se compila una tabla 2X2 de cuatro celdas. (ver Tabla 6). Tabla 6 en esta mesa O
Luego, con base en los datos de la tabla 2X2 (ver Tabla 6), se puede probar la hipótesis nula sobre la igualdad de las probabilidades de que los objetos del primer y segundo conjunto caigan en la primera (segunda) categoría de la escala para medir comprobándose la propiedad, por ejemplo, la hipótesis sobre la igualdad de probabilidades de realizar correctamente una determinada tarea por parte de los alumnos de las clases control y experimental. Al probar hipótesis nulas, no es necesario que las probabilidades pág. 1 y pág. 2 eran conocidas, ya que las hipótesis sólo establecen ciertas relaciones entre ellas (igualdad, más o menos). Para probar las hipótesis nulas discutidas anteriormente, de acuerdo con los datos de la tabla 2X2 (ver Tabla 6), se calcula el valor de las estadísticas del criterio T de acuerdo con la siguiente fórmula general:
donde n 1 , n 2 - tamaños de muestra,n=n1 + n2- número total de observaciones. Se prueba la hipótesis H0: pag 1 £ pag 2- con una alternativa H 1: p 1 > p 2. Dejar a - nivel de significación aceptado. Entonces el valor de la estadística T, obtenido sobre la base de datos experimentales se compara con el valor crítico de las estadísticas x1-2
a ,que viene determinado por la tabla do 2 do un grado de libertad (ver Apéndice 2) teniendo en cuenta el valor seleccionado a . Si la desigualdad es verdadera T<
x
1-2
a
, entonces se acepta la hipótesis nula en el nivel a .Si no se cumple esta desigualdad, entonces no tenemos motivos suficientes para rechazar la hipótesis nula. Debido al hecho de que la sustitución de la distribución exacta de las estadísticas T distribución do 2 do un grado de libertad da una aproximación bastante buena solo para muestras grandes, la aplicación del criterio está limitada por ciertas condiciones. 1) la suma de los volúmenes de dos muestras es inferior a 20; 2)al menos una de las frecuencias absolutas en la tabla 2X2 compilada a partir de datos experimentales es menor que 5. Ejemplo 6Se realizó un experimento con el objetivo de identificar los mejores libros de texto escritos por dos equipos de autores de acuerdo con los objetivos de la enseñanza de la geometría y el contenido del programa. IX clase. Para el experimento, se seleccionaron dos distritos por selección aleatoria, la mayoría de las escuelas en las que estaban ubicadas en áreas rurales. Los alumnos del primer distrito (20 grados) estudiaron de acuerdo con el libro de texto No. 1, los alumnos del segundo distrito (15 grados) estudiaron de acuerdo con el libro de texto No. 2. Consideremos el método de comparar las respuestas de los maestros de escuelas experimentales en dos distritos a una de las preguntas del cuestionario: "¿Está el libro de texto generalmente disponible para lectura independiente y ayuda a dominar el material que el maestro no explicó en clase (Respuesta: sí - no.) La actitud de los profesores hacia la propiedad estudiada de los libros de texto se mide en una escala de títulos, que tiene dos categorías: sí, no. Ambas muestras de docentes son aleatorias e independientes. Distribuiremos las respuestas de 20 docentes del primer distrito y 15 docentes del segundo distrito en dos categorías y las anotaremos en forma de tabla 2X2 (Tabla 5). Tabla 7 Todos los valores en la tabla. 7 no es inferior a 5, por lo tanto, de acuerdo con las condiciones para usar el criterio c 2 el cálculo de las estadísticas del criterio se realiza según la fórmula (9).
Según la tabla del Anexo 2
para un grado de libertad ( v=l ) y nivel de significancia a =0.05 encontrar x 1-
un un=T crítico = 3,84. Por lo tanto, la observación de la desigualdad T es verdadera<Т критич
(1,86<3,84). Согласно правилу принятия решений
для критерия
c 2 , el resultado obtenido no proporciona motivos suficientes para rechazar la hipótesis nula, es decir, los resultados de la encuesta a docentes en dos distritos experimentales no proporcionan motivos suficientes para rechazar el supuesto de disponibilidad equitativa de libros de texto №
1
y 2 para la lectura independiente de los estudiantes. El uso de la prueba de chi-cuadrado también es posible en el caso de que los objetos de dos muestras de dos poblaciones se distribuyan en más de dos categorías según el estado de la propiedad estudiada. Por ejemplo, los estudiantes de las clases experimentales y de control se dividen en cuatro categorías de acuerdo con las calificaciones (en puntos: 2, 3, 4, 5) que reciben los estudiantes por completar algún trabajo de control. Los resultados de medir el estado de la propiedad estudiada en los objetos de cada muestra se distribuyen en DE categorías. En base a estos datos, se elabora una tabla 2XC, en la que dos filas (según el número de poblaciones consideradas) y DE columnas (según el número de diferentes categorías del estado de la propiedad estudiada, adoptadas en el estudio). Tabla 8 Con base en los datos de la Tabla 8, es posible probar la hipótesis nula sobre la igualdad de las probabilidades de golpear los objetos del primer y segundo conjunto en cada uno dei (yo = yo ,2, ..., C) categorías, es decir, verificar el cumplimiento de todas las igualdades siguientes: pág. 11 \u003d pág. 21,
p 12 \u003d p 22, ..., p 1 c \u003d p 2 c. Es posible, por ejemplo, probar la hipótesis sobre la igualdad de las probabilidades de obtener notas "5", "4", "3" y "2" para la realización de una determinada tarea por parte de los estudiantes en las clases de control y experimental. . Para probar la hipótesis nula usando la prueba c 2
en base a los datos de la tabla 2XC, se calcula el valor de las estadísticas del criterio T de acuerdo con la siguiente fórmula:
dónde pág. 1 y pág. 2- tamaños de muestra. Sentido T, obtenido sobre la base de datos experimentales se compara con el valor crítico x 1-
a ,que viene determinado por la tabla c 2 c k =С-1 grados de libertad, teniendo en cuenta el nivel de significación elegido a . Cuando la desigualdad T > x 1-
un unla hipótesis nula se rechaza en el nivel a y se acepta la hipótesis alternativa. Esto significa que la distribución de objetos en DE categorías según el estado del inmueble estudiado es diferente en los dos conjuntos considerados. Ejemplo 7. Consideremos la metodología para comparar los resultados del trabajo escrito que puso a prueba la asimilación de una de las secciones del curso por parte de los estudiantes del primer y segundo distrito. Por selección aleatoria se elaboró una muestra de 50 personas entre los estudiantes del primer distrito que escribieron el trabajo, y una muestra de 50 personas entre los estudiantes de la segunda región. De acuerdo con criterios de evaluación de desempeño especialmente desarrollados, cada estudiante podría caer en una de cuatro categorías: malo, mediocre, bueno, excelente. Usamos los resultados del trabajo realizado por dos muestras de estudiantes para probar la hipótesis de que el libro de texto No. 1 contribuye a una mejor asimilación de la sección evaluada del curso, es decir, los estudiantes en la primera región experimental, en promedio, recibirán mayor notas que los estudiantes de la segunda región. Anotaremos los resultados del trabajo realizado por los alumnos de ambas muestras en forma de tabla de 2X4 (Tabla 9
).
Tabla 9 De acuerdo con los términos de uso del criterio c 2 las estadísticas de criterio se calculan según la fórmula corregida (10).
De acuerdo con las condiciones para aplicar una prueba de chi-cuadrado de dos colas según la tabla del Anexo 2
para un grado de libertad ( k Grabar M.I., Krasnyanskaya K.A. Aplicación de la estadística matemática en la investigación pedagógica. Métodos no paramétricos. M., Pedagogía, 1977, p.54 Grabar M.I., Krasnyanskaya K.A. Aplicación de la estadística matemática en la investigación pedagógica. Métodos no paramétricos. M., "Pedagogía", 1977, pág. 57
![]()
![]()
![]()
b) el caso de muestras vinculadas (pareadas)
 (6)
(6)


6.1.3 F - Prueba de Fisher
![]()
6.2 Pruebas no paramétricas
6.2.1 Criterio de signo ( criterio G)

6.2.2 Prueba de χ2 (chi-cuadrado)

 (9)
(9)


 (10)
(10)
![]()
El método discutido anteriormente funciona bien si la característica cualitativa que nos interesa toma dos valores (la trombosis es - no, el verde marciano - el rosa). Además, dado que el método es un análogo directo de la prueba t de Student, el número de muestras comparadas también debe ser igual a dos.
Está claro que tanto el número de valores de característica como el número de muestras pueden ser superiores a dos. Para analizar tales casos, se necesita un método diferente similar al análisis de varianza. En apariencia, este método, que ahora describiremos, es muy diferente del criterio z, pero de hecho hay mucho en común entre ellos.
Para no ir muy lejos en un ejemplo, comencemos con el problema de la trombosis del shunt que acabamos de analizar. Ahora consideraremos no la proporción, sino el número de pacientes con trombosis. Ingresaremos los resultados de la prueba en la tabla (Tabla 5.1). Para cada grupo indicamos el número de pacientes con y sin trombosis. Tenemos dos signos: el fármaco (aspirina-placebo) y la trombosis (sí-no); la tabla muestra todas sus combinaciones posibles, por lo que dicha tabla se llama tabla de contingencia. En este caso, el tamaño de la mesa es de 2x2.
Veamos las celdas ubicadas en la diagonal que va desde la esquina superior izquierda hasta la esquina inferior derecha. Los números en ellos son notablemente más grandes que los números en otras celdas de la tabla. Esto sugiere una asociación entre el uso de aspirina y el riesgo de trombosis.
Ahora echemos un vistazo a la tabla. 5.2. Esta es una tabla de números esperados que obtendríamos si la aspirina no afectara el riesgo de trombosis. Cómo calcular los números esperados, analizaremos un poco más abajo, pero por ahora prestaremos atención a las características externas de la tabla. Además de los números fraccionarios ligeramente aterradores en las celdas, uno puede notar una diferencia más en la tabla. 5.1 son los datos de resumen para los grupos en la columna de la derecha y para la trombosis en la fila inferior. En la esquina inferior derecha, el número total de pacientes en el ensayo. Sobre-
Nótese que aunque los números en los recuadros de la Fig. 5.1 y 5.2 son diferentes, las sumas en filas y columnas son las mismas.
¿Cómo calcular los números esperados? Placebo recibió 25 personas, aspirina - 19. La trombosis de la derivación ocurrió en 24 de los 44 examinados, es decir, en el 54,55% de los casos no ocurrió, en 20 de los 44, es decir, en el 45,45% de los casos. Aceptamos la hipótesis nula de que la aspirina no afecta el riesgo de trombosis. Luego se debe observar trombosis con igual frecuencia de 54,55% en los grupos placebo y aspirina. Habiendo calculado cuánto es el 54,55% de 25 y 19, obtenemos 13,64 y 10,36, respectivamente. Este es el número esperado de pacientes con trombosis en los grupos de placebo y aspirina. De la misma manera, puede obtener el número esperado de pacientes sin trombosis en el grupo de placebo: 45,45% de 25, es decir, 11,36 en el grupo de aspirina, 45,45% de 19, es decir, 8,64. Tenga en cuenta que los números esperados se calculan hasta el segundo decimal; dicha precisión será necesaria en cálculos posteriores.
Tabla de comparación. 5.1 y 5.2. Los números en las celdas son bastante diferentes. Por lo tanto, el cuadro real difiere del que se observaría si la aspirina no tuviera efecto sobre el riesgo de trombosis. Ahora resta construir un criterio que caracterice estas diferencias por un solo número, y luego encontrar su valor crítico, es decir, actuar como en el caso de los criterios F, t o z.
Sin embargo, primero, recordemos una característica más familiar.
una medida es el trabajo de Conahan que compara el halotano y la morfina, es decir, la parte donde se comparó la mortalidad operatoria. Los datos correspondientes se dan en la tabla. 5.3. La forma de la mesa es la misma que la mesa. 5.1. A su vez, Mesa 5.4 como tabla. 5.2 contiene números esperados, es decir, números calculados asumiendo que la letalidad es independiente del anestésico. De los 128 operados sobrevivieron 110, es decir, el 85,94%. Si la elección de la anestesia no afectara la mortalidad, entonces en ambos grupos la proporción de sobrevivientes sería la misma y el número de sobrevivientes estaría en el grupo de halotano - 85,94% de 61, es decir, 52,42 en el grupo de morfina - 85,94% de 67 , es decir, 57,58. De la misma manera, puede obtener el número esperado de muertes. Comparemos las tablas 5.3 y 5.4. A diferencia del ejemplo anterior, las diferencias entre los valores esperados y observados son muy pequeñas. Como descubrimos anteriormente, no hay diferencias en la mortalidad. Parece que estamos en el camino correcto.
Criterio x2 para una tabla 2x2
La prueba x2 (léase "chi-cuadrado") no requiere ninguna suposición sobre los parámetros de la población de la que se toman las muestras; esta es la primera de las pruebas no paramétricas que se nos presentan. Vamos a construirlo. Primero, como siempre, el criterio debe dar un solo número,
lo cual serviría como medida de la diferencia entre los datos observados y los esperados, es decir, en este caso, la diferencia entre la tabla de números observados y esperados. En segundo lugar, el criterio debe tener en cuenta que la diferencia, digamos, en un paciente es más importante para un número esperado pequeño que para uno grande.
Definimos el criterio x2 de la siguiente manera:
donde O es el número observado en la celda de la tabla de contingencia, E es el número esperado en la misma celda. La suma se realiza sobre todas las celdas de la tabla. Como puede verse en la fórmula, cuanto mayor sea la diferencia entre los números observados y esperados, mayor será la contribución de la celda al valor de %2. Al mismo tiempo, las celdas con un número esperado pequeño contribuyen más. Por lo tanto, el criterio satisface ambos requisitos: en primer lugar, mide las diferencias y, en segundo lugar, tiene en cuenta su magnitud en relación con los números esperados.
Apliquemos el criterio x2 a los datos de trombosis de derivación. En mesa. 5.1 muestra los números observados, y en la tabla. 5.2 - esperado.
![]()
lo y el valor z obtenido a partir de los mismos datos. Se puede demostrar que para tablas cruzadas de tamaño 2x2, se cumple la igualdad X2 = z2.
El valor crítico %2 se puede encontrar de forma familiar. En la fig. En la figura 5.7 se muestra la distribución de posibles valores de X2 para tablas de contingencia 2x2 para el caso en que no exista relación entre las características estudiadas. El valor de X2 supera 3,84 solo en el 5% de los casos. Por tanto, 3,84 es el valor crítico para el nivel de significancia del 5%. En el ejemplo de la trombosis de la derivación, obtuvimos un valor de 7,10, por lo que rechazamos la hipótesis de que no existe una asociación entre la ingesta de aspirina y los coágulos sanguíneos. Por el contrario, los datos de Table. 5.3 están en buen acuerdo con la hipótesis del mismo efecto del halotano y la morfina en la tasa de mortalidad postoperatoria.
Por supuesto, como todos los criterios de significación, x2 da una evaluación probabilística de la verdad de una hipótesis particular. De hecho, la aspirina puede no afectar el riesgo de trombosis. De hecho, el halotano y la morfina pueden tener diferentes efectos sobre la mortalidad operatoria. Pero, como mostró el criterio, ambos son improbables.
La aplicación del criterio x2 es válida si el número esperado en alguna de las celdas es mayor o igual a 5. Esta condición es similar a la condición de aplicabilidad del criterio z.
El valor crítico %2 depende del tamaño de la tabla de contingencia, es decir, del número de tratamientos comparados (filas de la tabla) y del número de resultados posibles (columnas de la tabla). El tamaño de la mesa se expresa por el número de grados de libertad v:
V \u003d (r - 1) (s - 1),
donde r es el número de filas y c es el número de columnas. Para tablas de 2x2 tenemos v = (2 - l)(2 - l) = l. Los valores críticos de %2 para diferentes v se dan en la Tabla. 5.7.
La fórmula dada anteriormente para x2 en el caso de una tabla de 2x2 (es decir, con 1 grado de libertad) da valores algo sobreestimados (una situación similar fue con el criterio z). Esto se debe a que la distribución teórica de x2 es continua, mientras que el conjunto de valores de x2 calculados es discreto. En la práctica, esto conducirá a que la hipótesis nula sea rechazada con demasiada frecuencia. Para compensar este efecto, se introduce la corrección de Yeats en la fórmula: (1 O - E - -
Tenga en cuenta que la corrección de Yeats solo se aplica cuando v = 1, es decir, para tablas de 2x2.
Apliquemos la corrección de Yeats al estudio de la asociación entre la ingesta de aspirina y la trombosis de la derivación (Tablas 5.1 y 5.2):
Como recordará, sin la corrección de Yates, el valor de %2 era 7,10. El valor corregido de %2 fue inferior a 6,635, el valor crítico para el nivel de significación del 1 %, pero aún superó 5,024, el valor crítico para el nivel de significación del 2,5 %.
Criterio x2 para una tabla de contingencia arbitraria
Ahora considere el caso cuando la tabla de contingencia tiene más de dos filas o columnas. Tenga en cuenta que el criterio z no es aplicable en tales casos.
Pulgada. 3 hemos demostrado que correr reduce el número de periodos*. ¿Estos cambios lo impulsan a ver a un médico? En mesa. 5.5 muestra los resultados de una encuesta a los participantes del estudio. ¿Estos datos respaldan la hipótesis de que correr no afecta la probabilidad de ver a un médico por períodos irregulares?
De las 165 mujeres examinadas, 69 (es decir, el 42%) fueron al médico, las restantes 96 (es decir, el 58%) no fueron al médico. si un
* Al mismo tiempo, para simplificar los cálculos, se asumió que los tamaños de los tres grupos (control, atletas femeninas y atletas) eran iguales. Ahora usaremos datos reales.
trotar no afecta la probabilidad de visitar a un médico, entonces en cada uno de los grupos el 42% de las mujeres deberían haber consultado a un médico. En mesa. 5.6 muestra los valores esperados correspondientes. ¿Los datos reales son muy diferentes a ellos?
Para responder a esta pregunta, calculamos %2:
(14 - 22,58)2 (40 - 31,42)2 (9 - 9,62)2
22,58 31,42 9,62
(14 - 13,38)2 (46 - 36,80)2 (42 - 51,20)2
13,38 36,80 51,20
El número de filas en la tabla de contingencia es tres, las columnas son dos, por lo que el número de grados de libertad v = (3 - 1)(2 - 1) = 2. Si la hipótesis de ausencia de diferencias entre grupos es correcta, entonces, como se puede ver en la Tabla. 5.7, %2 excederá 9.21 no más del 1% del tiempo. El valor resultante es mayor. Así, a un nivel de significación de 0,01, podemos rechazar la hipótesis de que no existe relación entre correr y las visitas al médico por la menstruación. Sin embargo, habiendo descubierto que la conexión existe, nosotros, sin embargo, no podremos indicar qué (cuáles) grupos difieren del resto.
Entonces, nos familiarizamos con el criterio %2. Aquí está el orden de su aplicación.
Construya una tabla de contingencia basada en los datos disponibles.
Cuente la cantidad de objetos en cada fila y en cada columna y encuentre qué proporción del número total de objetos forman estos valores.
Conociendo estas fracciones, calcule los números esperados con una precisión de dos decimales: el número de objetos que
golpearía todas las celdas de la tabla si no hubiera una relación entre filas y columnas
Encuentre un valor que caracterice las diferencias entre los valores observados y esperados. Si la tabla de contingencia es 2x2, aplique la corrección de Yeats
Calcule el número de grados de libertad, seleccione el nivel de significación y de acuerdo con la tabla. 5.7, determine el valor crítico %2. Compáralo con el que tienes para tu mesa.
Recuerde, para tablas de referencias cruzadas de 2x2, el criterio x2 solo se aplica si todos los números esperados son mayores que 5. ¿Qué sucede con las tablas más grandes? En este caso, el criterio %2 es aplicable si todos los números esperados son al menos 1 y la proporción de celdas con números esperados inferiores a 5 no supera el 20 %. Si no se cumplen estas condiciones, el criterio x2 puede dar resultados falsos. En este caso, se pueden recopilar datos adicionales, pero esto no siempre es factible. Hay una manera más fácil: combinar varias filas o columnas. Le mostraremos cómo hacer esto a continuación.
Conversión de tablas cruzadas
En el apartado anterior establecimos la existencia de una asociación entre el jogging y las visitas al médico por la menstruación, o, lo que es lo mismo, la existencia de diferencias entre grupos en la frecuencia de visitas al médico. Sin embargo, no pudimos determinar qué grupos son diferentes entre sí y cuáles no. Encontramos una situación similar en el análisis de varianza. Al comparar varios grupos, el análisis de varianza permite detectar el hecho mismo de la existencia de diferencias, pero no indica los grupos que se destacan. Esto último puede hacerse por los procedimientos de comparación múltiple, que discutimos en el Cap. 4. Algo similar se puede hacer con las tablas de contingencia.
Mirando la mesa. 5.5, se puede suponer que las atletas y deportistas iban al médico con más frecuencia que las mujeres del grupo de control. La diferencia entre mujeres atletas y mujeres atletas parece ser insignificante.
Probemos la hipótesis de que las atletas y atletas
| V | 0,50 | 0,25 | 0,10 | 0,05 | 0,025 | 0,01 | 0,005 | 0,001 |
| 41 | 40,335 | 46,692 | 52,949 | 56,942 | 60,561 | 64,950 | 68,053 | 74,745 |
| 42 | 41,335 | 47,766 | 54,090 | 58,124 | 61,777 | 66,206 | 69,336 | 76,084 |
| 43 | 42,335 | 48,840 | 55,230 | 59,304 | 62,990 | 67,459 | 70,616 | 77,419 |
| 44 | 43,335 | 49,913 | 56,369 | 60,481 | 64,201 | 68,710 | 71,893 | 78,750 |
| 45 | 44,335 | 50,985 | 57,505 | 61,656 | 65,410 | 69,957 | 73,166 | 80,077 |
| 46 | 45,335 | 52,056 | 58,641 | 62,830 | 66,617 | 71,201 | 74,437 | 81,400 |
| 47 | 46,335 | 53,127 | 59,774 | 64,001 | 67,821 | 72,443 | 75,704 | 82,720 |
| 48 | 47,335 | 54,196 | 60,907 | 65,171 | 69,023 | 73,683 | 76,969 | 84,037 |
| 49 | 48,335 | 55,265 | 62,038 | 66,339 | 70,222 | 74,919 | 78,231 | 85,351 |
| 50 | 49,335 | 56,334 | 63,167 | 67,505 | 71,420 | 76,154 | 79,490 | 86,661 |
| Nivel significativo |
| J. H. Zar, Biostatistical Analysis, 2.ª edición, Prentice-Hall, Englewood Cliffs, N.J., 1984. |
k ir al médico con la misma frecuencia. Para hacer esto, seleccione una subtabla de la tabla original que contenga datos para estos dos grupos. En mesa. 5.8 muestra los números observados y esperados; están bastante cerca.
Prueba estadística
La regla por la cual se rechaza o acepta la hipótesis R 0 se llama criterio estadístico. El nombre del criterio, por regla general, contiene una letra, que denota una característica especialmente recopilada del párrafo 2 del algoritmo estadístico de prueba de hipótesis (ver párrafo 4.1), calculada en el criterio. Bajo las condiciones de este algoritmo, el criterio se llamaría "en-criterio".
Al probar hipótesis estadísticas, son posibles dos tipos de errores:
- - error de primer tipo(puede rechazar la hipótesis I 0 cuando en realidad es verdadera);
- - error de tipo II(puede aceptar la hipótesis I 0 cuando en realidad no es cierta).
Probabilidad a cometer un error tipo uno se llama el nivel de significación del criterio.
Si por R denotemos la probabilidad de cometer un error tipo II, entonces (l -R)- la probabilidad de no cometer un error tipo II, que se denomina El poder del criterio.
Bondad de ajuste x 2 Pearson
Hay varios tipos de hipótesis estadísticas:
- - sobre la ley de distribución;
- - homogeneidad de las muestras;
- - valores numéricos de parámetros de distribución, etc.
Consideraremos la hipótesis sobre la ley de distribución en el ejemplo de la prueba de bondad de ajuste x 2 de Pearson.
criterio de concordancia llamada prueba estadística para probar la hipótesis nula sobre la supuesta ley de la distribución desconocida.
La prueba de bondad de ajuste de Pearson se basa en una comparación de frecuencias empíricas (observadas) y teóricas de observaciones calculadas bajo el supuesto de una determinada ley de distribución. La hipótesis # 0 aquí se formula de la siguiente manera: la población general se distribuye normalmente de acuerdo con el criterio en estudio.
Algoritmo de prueba de hipótesis estadística #0 para criterios x1 Pearson:
- 1) presentamos la hipótesis R 0: según el criterio en estudio, la población general se distribuye normalmente;
- 2) calcular la media de la muestra y la desviación estándar de la muestra sobre en;
3) según el volumen de muestra disponible PAGS calculamos una característica compilada especialmente,
donde: i, - frecuencias empíricas,  - frecuencias teóricas,
- frecuencias teóricas,
PAGS - tamaño de la muestra,
h- el valor del intervalo (la diferencia entre dos opciones adyacentes),
Valores normalizados de la característica observada,
![]() - función de tabla. También frecuencias teóricas
- función de tabla. También frecuencias teóricas
se puede calcular usando la función estándar de MS Excel DISTR.NORM según la fórmula;
4) de acuerdo con la distribución de muestreo, determinamos el valor crítico de una característica especialmente compilada XLP
5) cuando se rechaza la hipótesis #0, cuando se acepta la hipótesis #0.
Ejemplo. Considere el signo X- el valor de los indicadores de prueba para los convictos en una de las colonias correccionales según alguna característica psicológica, presentado como una serie de variación:
Con un nivel de significación de 0,05, pruebe la hipótesis de una distribución normal de la población general.
1. Con base en la distribución empírica, puede presentar una hipótesis H 0: según el criterio en estudio "el valor del indicador de prueba para una determinada característica psicológica", la población en general
el número de hijos se distribuye normalmente. Hipótesis alternativa 1: según el rasgo estudiado “el valor del indicador de prueba para esta característica psicológica”, la población general de reclusos no tiene una distribución normal.
2. Calcular las características numéricas de la muestra:

|
Intervalos |
x y y |
X) sch |
 |
||||
3. Calcular una característica especialmente compuesta j 2 . Para ello, en la penúltima columna de la tabla anterior encontramos las frecuencias teóricas mediante la fórmula, y en la última columna
calculemos la característica % 2 . Obtenemos x2 = 0,185.
Para mayor claridad, construiremos un polígono de la distribución empírica y una curva normal según frecuencias teóricas (Fig. 6).

Arroz. 6.
4. Determinar el número de grados de libertad s: k = 5, t = 2, s = 5-2-1 = 2.
Según la tabla o utilizando la función estándar de MS Excel "XI20BR" para el número de grados de libertad 5 = 2 y el nivel de significancia un = 0.05 encuentre el valor crítico del criterio xl p.=5,99. Por nivel de significancia a= 0,01 valor crítico del criterio X%. = 9,2.
5. Valor observado del criterio X=0.185 menos que todos los valores encontrados Hc R.-> por lo tanto, se acepta la hipótesis R 0 en ambos niveles de significancia. La discrepancia entre las frecuencias empírica y teórica es insignificante. Por lo tanto, los datos observacionales son consistentes con la hipótesis de una distribución poblacional normal. Así, según el rasgo estudiado “el valor del indicador de prueba para esta característica psicológica”, la población general de reclusos se distribuye normalmente.
- 1. Koryachko A.V., Kulichenko A.G. Matemáticas Superiores y Métodos Matemáticos en Psicología: Una Guía de Estudios Prácticos para Estudiantes de la Facultad de Psicología. Riazán, 1994.
- 2. Nasledov A. D. Métodos matemáticos de investigación psicológica. Análisis e interpretación de datos: Libro de texto, manual. SPb., 2008.
- 3. Sidorenko EV Métodos de procesamiento matemático en psicología. SPb., 2010.
- 4. Soshnikova LA y otros Análisis estadístico multivariado en la economía: Textbook, manual para universidades. M, 1999.
- 5. Sukhodolsky E.V. Métodos matemáticos en psicología. Jarkov, 2004.
- 6. Shmoylova R.A., Minashkin V.E., Sadovnikova N.A. Taller de teoría de la estadística: Libro de texto, manual. M, 2009.
- Gmurman V. E. Teoría de la Probabilidad y Estadística Matemática. S 465.
La prueba de chi-cuadrado de Pearson es un método no paramétrico que le permite evaluar la importancia de las diferencias entre el número real (revelado como resultado del estudio) de resultados o características cualitativas de la muestra que se incluyen en cada categoría y el número teórico que se puede esperar en los grupos estudiados si la hipótesis nula es cierta. En términos más simples, el método le permite evaluar la importancia estadística de las diferencias entre dos o más indicadores relativos (frecuencias, acciones).
1. Historia del desarrollo del criterio χ 2
La prueba de chi-cuadrado para el análisis de tablas de contingencia fue desarrollada y propuesta en 1900 por un matemático, estadístico, biólogo y filósofo inglés, fundador de la estadística matemática y uno de los fundadores de la biometría. Karl Pearson(1857-1936).
2. ¿Para qué se utiliza el criterio de la χ 2 de Pearson?
La prueba de chi-cuadrado se puede aplicar en el análisis. tablas de contingencia que contiene información sobre la frecuencia de los resultados en función de la presencia de un factor de riesgo. Por ejemplo, tabla de contingencia de cuatro campos como sigue:
| Éxodo es (1) | Sin salida (0) | Total | |
| Hay un factor de riesgo (1) | A | B | A+B |
| Sin factor de riesgo (0) | C | D | C+D |
| Total | A+C | B + D | A+B+C+D |
¿Cómo llenar una tabla de contingencia de este tipo? Consideremos un pequeño ejemplo.
Se está realizando un estudio sobre el efecto del tabaquismo en el riesgo de desarrollar hipertensión arterial. Para esto, se seleccionaron dos grupos de sujetos: el primero incluyó a 70 personas que fuman al menos 1 paquete de cigarrillos al día, el segundo, 80 no fumadores de la misma edad. En el primer grupo, 40 personas tenían presión arterial alta. En el segundo, se observó hipertensión arterial en 32 personas. En consecuencia, la presión arterial normal en el grupo de fumadores estaba en 30 personas (70 - 40 = 30) y en el grupo de no fumadores - en 48 (80 - 32 = 48).
Rellenamos la tabla de contingencia de cuatro campos con los datos iniciales:
En la tabla de contingencia resultante, cada línea corresponde a un grupo específico de sujetos. Columnas: muestran el número de personas con hipertensión arterial o con presión arterial normal.
El desafío para el investigador es: ¿existen diferencias estadísticamente significativas entre la frecuencia de personas con presión arterial entre fumadores y no fumadores? Puede responder a esta pregunta calculando la prueba de chi-cuadrado de Pearson y comparando el valor resultante con el crítico.
3. Condiciones y restricciones en el uso de la prueba chi-cuadrado de Pearson
- Los indicadores comparables deben medirse en escala nominal(por ejemplo, el género del paciente - masculino o femenino) o en ordinal(por ejemplo, el grado de hipertensión arterial, tomando valores de 0 a 3).
- Este método permite el análisis no solo de tablas de cuatro campos, cuando tanto el factor como el resultado son variables binarias, es decir, tienen solo dos valores posibles (por ejemplo, masculino o femenino, la presencia o ausencia de una determinada enfermedad en Historia ...). La prueba de chi-cuadrado de Pearson también se puede utilizar en el caso del análisis de tablas de campos múltiples, cuando el factor y (o) el resultado toman tres o más valores.
- Los grupos emparejados deben ser independientes, es decir, la prueba de chi-cuadrado no debe usarse cuando se comparan las observaciones de antes y después. prueba de McNemar(al comparar dos poblaciones relacionadas) o calculado Prueba Q Cochran(en caso de comparar tres o más grupos).
- Al analizar tablas de cuatro campos Valores esperados en cada una de las celdas debe ser al menos 10. En caso de que en al menos una celda el fenómeno esperado tome un valor de 5 a 9, se debe calcular la prueba de chi-cuadrado con corrección de Yates. Si en al menos una celda el fenómeno esperado es menor que 5, entonces el análisis debe usar Prueba exacta de Fisher.
- En el caso de análisis de tablas multicampo, el número esperado de observaciones no debe tomar valores inferiores a 5 en más del 20% de las celdas.
4. ¿Cómo calcular la prueba chi-cuadrado de Pearson?
Para calcular la prueba de chi-cuadrado, debe:

Este algoritmo es aplicable tanto para tablas de cuatro campos como para tablas de varios campos.
5. ¿Cómo interpretar el valor de la prueba chi-cuadrado de Pearson?
En el caso de que el valor obtenido del criterio χ 2 sea mayor que el crítico, concluimos que existe una relación estadística entre el factor de riesgo estudiado y el resultado en el nivel de significación adecuado.
6. Un ejemplo de cálculo de la prueba chi-cuadrado de Pearson
Determinemos la significancia estadística de la influencia del factor tabaquismo en la incidencia de hipertensión arterial según la tabla anterior:
- Calculamos los valores esperados para cada celda:
- Encuentre el valor de la prueba chi-cuadrado de Pearson:
χ 2 \u003d (40-33.6) 2 / 33.6 + (30-36.4) 2 / 36.4 + (32-38.4) 2 / 38.4 + (48-41.6) 2 / 41.6 \u003d 4.396.
- El número de grados de libertad f = (2-1)*(2-1) = 1. Encontramos el valor crítico de la prueba chi-cuadrado de Pearson de la tabla, que, a un nivel de significancia de p=0.05 y el número de grados de libertad 1, es 3.841.
- Comparamos el valor obtenido de la prueba de chi-cuadrado con el crítico: 4,396 > 3,841, por tanto, la dependencia de la incidencia de hipertensión arterial de la presencia de tabaquismo es estadísticamente significativa. El nivel de significación de esta relación corresponde a p<0.05.
Considere la aplicación enEMSOBRESALIRPrueba de chi-cuadrado de Pearson para probar hipótesis simples.
Después de recibir datos experimentales (es decir, cuando hay algo muestra) por lo general, se elige una ley de distribución que describa mejor la variable aleatoria representada por el muestreo. La verificación de qué tan bien se describen los datos experimentales por la ley de distribución teórica elegida se lleva a cabo usando criterios de consentimiento. hipótesis nula, suele haber una hipótesis de que la distribución de una variable aleatoria es igual a alguna ley teórica.
Primero veamos la aplicación. Prueba de bondad de ajuste de Pearson X 2 (chi-cuadrado) en relación con hipótesis simples (se supone que se conocen los parámetros de la distribución teórica). Luego - , cuando solo se especifica la forma de distribución, y los parámetros de esta distribución y el valor Estadísticas 2x2 se estiman/calculan sobre la base de los mismos muestras.
Nota: En la literatura en lengua inglesa, el procedimiento de solicitud Prueba de bondad de ajuste de Pearson 2x2 tiene un nombre La prueba de bondad de ajuste chi-cuadrado.
Recuerde el procedimiento para probar hipótesis:
- establecido muestras se calcula el valor Estadísticas, que corresponde al tipo de hipótesis que se está probando. Por ejemplo, para usar t-Estadísticas(si no se sabe);
- sujeto a la verdad hipótesis nula, la distribución de este Estadísticas conocido y se puede utilizar para calcular probabilidades (por ejemplo, para t- Estadísticas esto es );
- calculado en base a muestras sentido Estadísticas comparado con el valor crítico para el valor dado ();
- hipótesis nula rechazado si el valor Estadísticas mayor que el crítico (o si la probabilidad de obtener este valor Estadísticas() menos Nivel significativo, que es el enfoque equivalente).
gastemos prueba de hipótesis para diferentes distribuciones.
caso discreto
Supongamos que dos personas están jugando a los dados. Cada jugador tiene su propio juego de dados. Los jugadores se turnan para lanzar 3 dados a la vez. Cada ronda la gana el que lanza más seises a la vez. Los resultados se registran. Uno de los jugadores, después de 100 rondas, tuvo la sospecha de que los huesos de su oponente no eran simétricos, porque. a menudo gana (a menudo lanza seises). Decidió analizar qué tan probable es tal número de resultados de los oponentes.
Nota: Porque 3 dados, luego puedes tirar 0 a la vez; una; 2 o 3 seises, es decir variable aleatoria puede tomar 4 valores.
De la teoría de la probabilidad, sabemos que si los cubos son simétricos, entonces la probabilidad de que caigan seises obedece. Por lo tanto, después de 100 rondas, las frecuencias de los seis se pueden calcular usando la fórmula
=DIST.BINOM(A7,3,1/6,FALSO)*100
La fórmula asume que la celda A7 contiene el número correspondiente de seises caídos en una ronda.
Nota: Los cálculos se dan en archivo de ejemplo en hoja Discreto.
Para comparacion observado(Observado) y frecuencias teóricas(Esperado) cómodo de usar.

Con una desviación significativa de las frecuencias observadas de la distribución teórica, hipótesis nula sobre la distribución de una variable aleatoria según una ley teórica, debe ser rechazada. Es decir, si los dados del oponente no son simétricos, entonces las frecuencias observadas serán "significativamente diferentes" de Distribución binomial.
En nuestro caso, a primera vista, las frecuencias son bastante cercanas y es difícil sacar una conclusión inequívoca sin cálculos. Aplicable Prueba de bondad de ajuste de Pearson X 2, de modo que en lugar de la declaración subjetiva "significativamente diferente", que se puede hacer sobre la base de la comparación histogramas, use una declaración matemáticamente correcta.
Usemos el hecho de que ley de los grandes numeros frecuencia observada (observada) con volumen creciente muestras n tiende a la probabilidad correspondiente a la ley teórica (en nuestro caso, ley binomial). En nuestro caso, el tamaño de muestra n es 100.
vamos a presentar prueba Estadísticas, que denotamos por X 2:

donde O l es la frecuencia observada de eventos en que la variable aleatoria ha tomado ciertos valores aceptables, E l es la correspondiente frecuencia teórica (Esperada). L es el número de valores que puede tomar una variable aleatoria (en nuestro caso es igual a 4).
Como se puede ver en la fórmula, este Estadísticas es una medida de la proximidad de las frecuencias observadas a las teóricas, es decir se puede utilizar para estimar las "distancias" entre estas frecuencias. Si la suma de estas "distancias" es "demasiado grande", entonces estas frecuencias son "sustancialmente diferentes". Está claro que si nuestro cubo es simétrico (es decir, aplicable ley binomial), entonces la probabilidad de que la suma de "distancias" sea "demasiado grande" será pequeña. Para calcular esta probabilidad, necesitamos conocer la distribución Estadísticas X2 ( Estadísticas X 2 calculado en base al azar muestras, por lo que es una variable aleatoria y, por tanto, tiene su propia Distribución de probabilidad).
De un análogo multidimensional Teorema integral de Moivre-Laplace se sabe que para n->∞ nuestra variable aleatoria X 2 es asintóticamente con L - 1 grados de libertad.
Entonces, si el valor calculado Estadísticas X 2 (la suma de las “distancias” entre frecuencias) será mayor que cierto valor límite, entonces tendremos razón para rechazar hipótesis nula. como en la comprobación hipótesis paramétricas, el valor límite se ajusta mediante Nivel significativo. Si la probabilidad de que el estadístico X 2 tome un valor menor o igual al calculado ( pags-sentido) será menor Nivel significativo, después hipótesis nula puede ser rechazado.
En nuestro caso, el valor estadístico es 22.757. La probabilidad de que el estadístico X 2 tome un valor mayor o igual a 22,757 es muy pequeña (0,000045) y se puede calcular mediante las fórmulas
=XI2.DIST.PX(22,757;4-1) o
=XI2.PRUEBA(Observado; Esperado)
Nota: La función CH2.TEST() está específicamente diseñada para probar la relación entre dos variables categóricas (ver ).
La probabilidad de 0.000045 es significativamente menor de lo habitual Nivel significativo 0.05. Entonces, el jugador tiene todas las razones para sospechar que su oponente es deshonesto ( hipótesis nula se niega su honestidad).

cuando se aplica criterio X 2 se debe tener cuidado para asegurar que el volumen muestras n era lo suficientemente grande, de lo contrario, la aproximación de la distribución no sería válida estadísticas x 2. Se suele considerar que para esto es suficiente que las frecuencias observadas (Observadas) sean mayores a 5. De no ser así, entonces las bajas frecuencias se combinan en una o se unen a otras frecuencias, y al valor combinado se le asigna el total probabilidad y, en consecuencia, el número de grados de libertad disminuye X 2 -distribución.
Para mejorar la calidad de la aplicación criterio X 2(), es necesario reducir los intervalos de partición (aumentar L y, en consecuencia, aumentar el número grados de libertad), sin embargo, esto se evita mediante una restricción en el número de observaciones que caen en cada intervalo (d.b.>5).
caso continuo
Prueba de bondad de ajuste de Pearson 2x2 se puede aplicar de la misma manera en el caso de .
Considere algunos muestreo, que consta de 200 valores. Hipótesis nula Establece que muestra Hecho de .
Nota: Variables aleatorias en archivo de muestra en hoja continua generado usando la fórmula =NORM.EST.INV(ALEATORIO()). Por lo tanto, nuevos valores muestras se generan cada vez que se recalcula la hoja.
Se puede evaluar visualmente si el conjunto de datos disponible es adecuado.

Como puede ver en el diagrama, los valores de muestra se ajustan bastante bien a lo largo de la línea recta. Sin embargo, como en para prueba de hipótesis aplicable Prueba de bondad de ajuste de Pearson X 2 .
Para ello, dividimos el rango de variación de una variable aleatoria en intervalos con un paso de 0,5. Calculemos las frecuencias observadas y teóricas. Calculamos las frecuencias observadas usando la función FREQUENCY() y las teóricas usando la función NORM.ST.DIST().
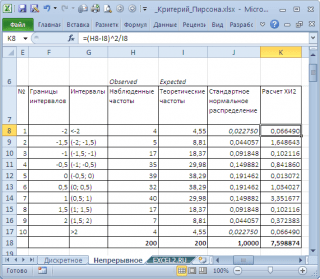
Nota: Como para caso discreto, es necesario asegurarse de que muestra fue bastante grande, y más de 5 valores cayeron en el intervalo.
Calcule las estadísticas X 2 y compárelas con el valor crítico para un determinado Nivel significativo(0,05). Porque Dividimos el rango de variación de una variable aleatoria en 10 intervalos, entonces el número de grados de libertad es 9. El valor crítico se puede calcular mediante la fórmula
\u003d XI2.INV.RH (0.05; 9) o
\u003d XI2.OBR (1-0.05; 9)
El gráfico anterior muestra que el valor de la estadística es 8.19, que es significativamente más alto crítico – hipótesis nula no es rechazado.
A continuación se muestra en qué muestra asumió un valor improbable, y sobre la base de criterios El consentimiento de Pearson X 2 se rechazó la hipótesis nula (a pesar de que los valores aleatorios se generaron mediante la fórmula =NORM.EST.INV(ALEATORIO()) Proporcionar muestreo de distribución normal estándar).

Hipótesis nula rechazada, aunque visualmente los datos se acercan bastante a una línea recta.
Como ejemplo, tomemos también muestreo de U(-3; 3). En este caso, incluso del gráfico es claro que hipótesis nula debe ser rechazado.

Criterio El consentimiento de Pearson X 2 también confirma que hipótesis nula debe ser rechazado.
-
 17 de abril de 2015En la serie armónica de Fourier
17 de abril de 2015En la serie armónica de Fourier -
 17 de abril de 2015Programas gratuitos para Windows descarga gratuita
17 de abril de 2015Programas gratuitos para Windows descarga gratuita
?")






