Оптимизация запросов mysql. Избегайте вложенных запросов
→ Оптимизация запросов MySQL
MySQL располагает большим набором функций для различных сортировок (ORDER BY ), группировок (GROUP BY ), объединений (LEFT JOIN или RIGHT JOIN ) и так далее. Все они безусловно удобны, но в условиях одноразовых запросов. К примеру, если лично Вам требуется что-то откопать в базе используя кучу таблиц и связок, то кроме вышеперечисленных функций можно и даже нужно применять условный операторы IF . Главная ошибка начинающих программистов это стремление применить такие запросы в рабочем коде сайта. В данном случае сложный запрос безусловно красив, но вреден. Все дело в том, что любые операторы сортировок, группировок, объединений или вложенных запросов, не могут выполняться в оперативной памяти, и используют жесткий диск для создания временных таблиц. А хард, как известно - самое узкое место сервера.
Правила оптимизации mysql запросов
1. Избегайте вложенных запросов
Это самая серьезная ошибка. Родительский процесс всегда будет ждать завершения дочернего и в это время держать коннект к базе, использовать диск и нагружать iowait. Два параллельных запроса в базу и выполнения нужных фильтраций в серверном интерпретаторе (Perl , PHP и т. д.), выполнятся на порядок быстрее чем вложенный.
Примеры на perl , как делать не следует:
My $sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)"); $sth->execute(); while (my @row = $sth->fetchrow_array()) { my $groupNAME = $dbh->selectrow_array("SELECT groupNAME FROM groups WHERE groupID = $row"); ### Допустим нужно собрать названия групп ### и добавить их в конец массива с данными push @row => $groupNAME; ### Делаем еще что-нибудь... }
или не в коем случае вот так:
My $sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(SELECT groupID FROM groups WHERE groupNAME = "Первая" OR groupNAME = "Вторая" OR groupNAME = "Седьмая")");
Если есть необходимость подобных действий, во всех случаях лучше использовать хеш, массив или любой другой путь для фильтрации.
Пример на perl, как делаю обычно я:
My %groups; my $sth = $dbh->prepare("SELECT groupID,groupNAME FROM groups WHERE groupID IN(2,3,7)"); $sth->execute(); while (my @row = $sth->fetchrow_array()) { $groups{$row} = $row; } ### А теперь выполням основную выборку без вложенного запроса my $sth2 = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)"); $sth2->execute(); while (my @row = $sth2->fetchrow_array()) { push @row => $groups{$row}; ### Делаем еще что-нибудь... }
2. Не сортируйте, не группируйте и не фильтруйте в базе
По возможности не применяйте в своих запросах операторы ORDER BY, GROUP BY, JOIN. Все они используют временные таблицы. Если сортировка или группировка необходима только для вывода элементов, например по алфавиту, лучше выполнить эти действия в переменных интерпретатора.
Примеры на perl, как сортировать не следует:
My $sth = $dbh->prepare("SELECT elementID,elementNAME FROM tbl WHERE groupID IN(2,3,7) ORDER BY elementNAME"); $sth->execute(); while (my @row = $sth->fetchrow_array()) { print qq{$row => $row}; }
Пример на perl, как сортирую обычно я:
My $list = $dbh->selectall_arrayref("SELECT elementID,elementNAME FROM tbl WHERE groupID IN(2,3,7)"); foreach (sort { $a-> cmp $b-> } @$list){ print qq{$_-> => $_->}; }
Так намного быстрее. Особенно заметна разница если данных много. В случае, если нужно отсортировать в perl по нескольким полям, можно применить сортировку Шварца . Если требуется произвольная сортировка ORDER BY RAND() - используйте сортировку random в perl .
3. Используйте индексы
Если от сортировки в базе можно отказаться в некоторых случаях, то от WHERE навряд ли удастся. Поэтому, для полей, по которым будет идти сравнение, необходимо устанавливать индексы. Делаются они просто.
Таким запросом:
ALTER TABLE `any_db`.`any_tbl` ADD INDEX `text_index`(`text_fld`(255));
Где 255 - длина ключа. Для некоторых типов данных он не требуется. Подробности в документации к MySQL.
В повседневной работе приходится сталкиваться с довольно однотипными ошибками при написании запросов.
В этой статье хотелось бы привести примеры того, как НЕ надо писать запросы.
- Выборка всех полей
SELECT * FROM tableПри написании запросов не используйте выборку всех полей - "*". Перечислите только те поля, которые вам действительно нужны. Это сократит количество выбираемых и пересылаемых данных. Кроме этого, не забывайте про покрывающие индексы. Даже если вам на самом деле необходимы все поля в таблице, лучше их перечислить. Во-первых, это повышает читабельность кода. При использовании звездочки невозможно узнать какие поля есть в таблице без заглядывания в нее. Во-вторых, со временем количество столбцов в вашей таблице может изменяться, и если сегодня это пять INT столбцов, то через месяц могут добавиться TEXT и BLOB поля, которые будут замедлять выборку.
- Запросы в цикле.
Нужно четко представлять себе, что SQL - язык, оперирующий множествами. Порой программистам, привыкшим думать терминами процедурных языков, трудно перестроить мышление на язык множеств. Это можно сделать довольно просто, взяв на вооружение простое правило - «никогда не выполнять запросы в цикле». Примеры того, как это можно сделать:1. Выборки
$news_ids = get_list("SELECT news_id FROM today_news ");
while($news_id = get_next($news_ids))
$news = get_row("SELECT title, body FROM news WHERE news_id = ". $news_id);Правило очень простое - чем меньше запросов, тем лучше (хотя из этого, как и из любого правила, есть исключения). Не забывайте про конструкцию IN(). Приведенный код можно написать одним запросом:
SELECT title, body FROM today_news INNER JOIN news USING(news_id)2. Вставки
$log = parse_log();
while($record = next($log))
query("INSERT INTO logs SET value = ". $log["value"]);Гораздо более эффективно склеить и выполнить один запрос:
INSERT INTO logs (value) VALUES (...), (...)3. Обновления
Иногда бывает нужно обновить несколько строк в одной таблице. Если обновляемое значение одинаковое, то все просто:
UPDATE news SET title="test" WHERE id IN (1, 2, 3).Если изменяемое значение для каждой записи разное, то это можно сделать таким запросом:
UPDATE news SET
title = CASE
WHEN news_id = 1 THEN "aa"
WHEN news_id = 2 THEN "bb" END
WHERE news_id IN (1, 2)Наши тесты показывают, что такой запрос выполняется в 2-3 раза быстрее, чем несколько отдельных запросов.
- Выполнение операций над проиндексированными полями
SELECT user_id FROM users WHERE blogs_count * 2 = $valueВ таком запросе индекс использоваться не будет, даже если столбец blogs_count проиндексирован. Для того, чтобы индекс использовался, над проиндексированным полем в запросе не должно выполняться преобразований. Для подобных запросов выносите функции преобразования в другую часть:
SELECT user_id FROM users WHERE blogs_count = $value / 2;Аналогичный пример:
SELECT user_id FROM users WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(registered) <= 10;Не будет использовать индекс по полю registered, тогда как
SELECT user_id FROM users WHERE registered >= DATE_SUB(CURRENT_DATE, INTERVAL 10 DAY);
будет. - Выборка строк только для подсчета их количества
$result = mysql_query(«SELECT * FROM table», $link);
$num_rows = mysql_num_rows($result);
Если вам нужно выбрать количество строк, удовлетворяющих определенному условию, используйте запрос SELECT COUNT(*) FROM table, а не выбирайте все строки лишь для того, чтобы подсчитать их количество. - Выборка лишних строк
$result = mysql_query(«SELECT * FROM table1», $link);
while($row = mysql_fetch_assoc($result) && $i < 20) {
…
}
Если вам нужны только n строк выборки, используйте LIMIT, вместо того, чтобы отбрасывать лишние строки в приложении. - Использование ORDER BY RAND()
SELECT * FROM table ORDER BY RAND() LIMIT 1;Если в таблице больше, чем 4-5 тысяч строк, то ORDER BY RAND() будет работать очень медленно. Гораздо более эффективно будет выполнить два запроса:
Если в таблице auto_increment"ный первичный ключ и нет пропусков:
$rnd = rand(1, query("SELECT MAX(id) FROM table"));
$row = query("SELECT * FROM table WHERE id = ".$rnd);Либо:
$cnt = query("SELECT COUNT(*) FROM table");
$row = query("SELECT * FROM table LIMIT ".$cnt.", 1");
что, однако, так же может быть медленным при очень большом количестве строк в таблице. - Использование большого количества JOIN"ов
SELECT
v.video_id
a.name,
g.genre
FROM
videos AS v
LEFT JOIN
link_actors_videos AS la ON la.video_id = v.video_id
LEFT JOIN
actors AS a ON a.actor_id = la.actor_id
LEFT JOIN
link_genre_video AS lg ON lg.video_id = v.video_id
LEFT JOIN
genres AS g ON g.genre_id = lg.genre_idНужно помнить, что при связи таблиц один-ко многим количество строк в выборке будет расти при каждом очередном JOIN"е. Для подобных случаев более быстрым бывает разбить подобный запрос на несколько простых.
- Использование LIMIT
SELECT… FROM table LIMIT $start, $per_pageМногие думают, что подобный запрос вернет $per_page записей (обычно 10-20) и поэтому сработает быстро. Он и сработает быстро для нескольких первых страниц. Но если количество записей велико, и нужно выполнить запрос SELECT… FROM table LIMIT 1000000, 1000020, то для выполнения такого запроса MySQL сначала выберет 1000020 записей, отбросит первый миллион и вернет 20. Это может быть совсем не быстро. Тривиальных путей решения проблемы нет. Многие просто ограничивают количество доступных страниц разумным числом. Также можно ускорить подобные запросы использованием покрывающих индексов или сторонних решений (например sphinx).
- Неиспользование ON DUPLICATE KEY UPDATE
$row = query("SELECT * FROM table WHERE id=1");If($row)
query("UPDATE table SET column = column + 1 WHERE id=1")
else
query("INSERT INTO table SET column = 1, id=1");Подобную конструкцию можно заменить одним запросом, при условии наличия первичного или уникального ключа по полю id:
INSERT INTO table SET column = 1, id=1 ON DUPLICATE KEY UPDATE column = column + 1
Иногда, формируя запрос, вы уже знаете, вам нужна только одна уникальная строка в таблице. Вы можете сформировать выборку по уникальной записи. Или вы можете просто запустить проверку на существование любого количества записей, которые удовлетворяют вашему условию.
В таких случаях, использование метода LIMIT 1 может существенно увеличить производительность:
// существуют ли в базе данные людей из Калифорнии? // НЕТ, таких нет!: $r = mysql_query("SELECT * FROM user WHERE state = "California""); if (mysql_num_rows($r) > 0) { // ... прочий код } // Положительный ответ $r = mysql_query("SELECT 1 FROM user WHERE state = "California" LIMIT 1"); if (mysql_num_rows($r) > 0) { // ... прочий код }
2. Оптимизация работы с базой с помощью обработки кэша запросов
Большинство серверов MySQL поддерживают функцию кэширования запросов. Это один из наиболее эффективных методов повышения производительности, с которым движок базы данных справляется без проблем.
Когда один и тот же запрос выполняется несколько раз, то, результат будет получен из кэша. Без необходимости обрабатывать снова все таблицы. Это значительно ускоряет процесс.
// если кэш запросов НЕ поддерживается $r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()"); // кэш поддерживается! $today_date = date("Y-m-d"); $r = mysql_query("SELECT username FROM user WHERE signup_date >= "$today_date"");
3. Индексация полей поиска
Индексы предназначены не только для присвоения первичному или уникальному ключам. Если в таблице есть столбцы, по которым вы производите поиск, их практически в обязательном порядке следует индексировать.
Как вы понимаете, это правило также распространяется на часть строки поиска: такую как «last_name LIKE ‘% ‘». Когда поиск производится по началу строки, MySQL может использовать для этого столбца индексацию.
Вы также должны понимать, какие виды запросов не могут использовать обычные индексы. Например, при поиске слова (например, «WHERE post_content LIKE ‘%tomato%"»), применение обычного индекса вам ничего не даст. В таком случае лучше будет использовать поиск MySQL на полное соответствие или создать свой собственный индекс.
4. Индексирование и использование столбцов одинакового типа при объединении
Если ваше приложение содержит много запросов на объединение, необходимо убедиться, что столбцы в обеих таблицах, которые вы объединяете, проиндексированы. Это влияет на оптимизацию внутренних операций MySQL по объединению.
Кроме того, столбцы, которые объединяются, должны быть одинакового типа. Например, если вы объединяете столбец типа DECIMAL из одной таблицы и столбец типа INT из другой, MySQL не сможет использовать по крайней мере один из индексов.
Даже кодировка символов должна быть того же типа для соответствующих строк объединяемых столбцов.
// ищем компании, находящиеся в моем штате $r = mysql_query("SELECT company_name FROM users LEFT JOIN companies ON (users.state = companies.state) WHERE users.id = $user_id"); // оба столбца штатов должны быть проиндексированы // и они оба должны быть одинакового типа и иметь ту же кодировку символов для соответствующих строк // или MySQL придется сканировать всю таблицу полностью
5. По возможности не используйте запросы типа SELECT *
Чем больше данных в таблице обрабатывается при запросе, тем медленнее выполняется сам запрос. Время уходит на дисковые операции. Кроме того, когда сервер базы данных разделен с веб-сервером, возникают задержки при передаче данных между серверами.
// нежелательный запрос $r = mysql_query("SELECT * FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welcome {$d["username"]}"; // лучше использовать следующий код: $r = mysql_query("SELECT username FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welcome {$d["username"]}";
6. Пожалуйста, не используйте метод сортировки ORDER BY RAND()
Это один из тех приемов, которые на первых порах кажутся неплохими, и многие программисты-новички попадаются на эту удочку. Вы даже не представляете, какую ловушку расставляете сами себе же, как только начинаете использовать в запросах этот фильтр.
Если вам действительно нужно отсортировать некоторые строки в результатах поиска, то есть гораздо более эффективные способы сделать это. Допустим, что вам нужно добавить дополнительный код к запросу, но из-за данной ловушки вы не сможете этого сделать, что приведет к уменьшению эффективности обработки данных, по мере того, как база будет разрастаться в размерах.
Проблема в том, что MySQL будет выполнять операцию RAND () (которая использует вычислительные ресурсы сервера) перед сортировкой для каждой строки в таблице. При этом выбираться будет всего одна строка.
// какой код НЕ следует использовать: $r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1"); // правильнее будет использовать следующий код: $r = mysql_query("SELECT count(*) FROM user"); $d = mysql_fetch_row($r); $rand = mt_rand(0,$d - 1); $r = mysql_query("SELECT username FROM user LIMIT $rand, 1");
Таким образом, вы выберете меньшее количество результатов поиска, после чего сможете применить метод LIMIT, описанный в пункте 1.
7. Используйте столбцы типа ENUM вместо VARCHAR
Столбцы типа ENUM очень компактны, а, следовательно, быстры в обработке. Внутри базы их содержание хранится в формате TINYINT , но они могут содержать и выводить любые значения. Поэтому в них очень удобно задавать определенные поля.
Если у вас есть некоторое поле, которое содержит несколько разных значений одного вида, то вместо столбцов типа VARCHAR лучше использовать ENUM. Например, это может быть столбец «Статус », который содержит только такие значения, как «активно », «неактивно », «ожидание », «срок действия истек » и т.д.
Существует даже возможность задать сценарий, при котором MySQL будет «предлагать» изменить структуру таблицы. Когда у вас есть поле типа VARCHAR, система может автоматически рекомендовать изменить формат столбца на ENUM. Это можно сделать с помощью вызова функции PROCEDURE ANALYSE() .
Используйте для хранения IP-адресов поля типа UNSIGNED INT
Многие разработчики создают для этих целей поля типа VARCHAR (15) , в то время как IP-адреса можно было бы хранить в базе в виде десятичных чисел. Поля типа INT предоставляют возможность хранить до 4 байта информации, и при этом для них можно задать фиксированный размер поля.
Вы должны удостовериться, что ваши колонки имеют формат UNSIGNED INT , поскольку IP-адрес задается 32-мя битами.
В запросах можно использовать параметр INET_ATON () для преобразования IP-адресов в десятичные числа, и INET_NTOA () — наоборот. PHP имеет и другие аналогичные функции long2ip () и ip2long () .
8. Вертикальное секционирование (разделение)
Вертикальное секционирование представляет собою процесс, когда структура таблицы разделяется по вертикали из соображений оптимизации работы с базой данных.
Пример 1: Допустим, у вас есть таблица пользователей, в которой в числе прочего содержатся их домашние адреса. Данная информация используется очень редко. Вы можете разделить вашу таблицу и хранить данные по адресам в другой таблице.
Таким образом, ваша основная таблица пользователей заметно уменьшится в размерах. А как вы знаете, меньшие таблицы, обрабатываются быстрее.
Пример 2: У вас в таблице есть поле «last_login » (последний логин). Оно обновляется каждый раз, когда пользователь входит в систему под своим именем пользователя. Но каждое изменение таблицы записывается в кэш запросов к этой таблице, который хранится на диске. Вы можете переместить это поле в другую таблицу, чтобы уменьшить количество обращений к вашей основной таблице пользователей.
Однако вы должны быть уверены в том, что обе таблицы, которые получились после секционирования, не будут в дальнейшем использоваться одинаково часто. В противном случае это существенно снизит производительность.
9. Меньшие столбцы – быстрее
Для движков баз данных дисковое пространство, пожалуй, самое узкое место. Поэтому хранить информацию более компактно, как правило, полезно с точки зрения производительности. Это уменьшает количество обращений к диску.
В MySQL Docs прописан ряд требований к хранению разных типов данных. Если ожидается, что таблица не будет содержать слишком большое количество записей, то нет причин хранить первичный ключ в полях типа INT, MEDIUMINT, SMALLINT , а в отдельных случаях даже TINYINT . Если в формате даты вам не нужны составляющие времени (часы: минуты), то используйте поля типа DATE вместо DATETIME.
Однако все же убедитесь, что на перспективу вы оставили себе достаточно пространства для развития. Иначе в какой-то момент может произойти что-то типа обвала.
От автора: один мой знакомый решил оптимизировать свой автомобиль. Сначала одно колесо снял, потому крышу спилил, затем мотор… В общем, сейчас он пешком ходит. Это все последствия неправильного подхода! Поэтому, чтобы ваша СУБД продолжала «ездить», оптимизация MySQL должна проходить правильно.
Когда оптимизировать и зачем?
Лишний раз лезть в настройки сервера и изменять значения параметров (особенно, если не знаете, чем это может закончиться) не стоит. Если рассматривать данную тему с «колокольни» улучшения производительности веб-ресурсов, то она настолько обширная, что ей нужно посвящать целое научное издание в 7 томах.
Но такого писательского терпения у меня явно нет, да и у вас читательского тоже. Мы поступим проще, и постараемся лишь слегка углубиться в чащи оптимизации MySQL сервера и его составляющих. С помощью оптимальной установки всех параметров СУБД можно достигнуть нескольких целей:
Увеличить скорость выполнения запросов.
Повысить общую производительность сервера.
Уменьшить время ожидания загрузки страниц ресурса.
Снизить потребление серверных мощностей хостинга.
Снизить объем занимаемого дискового пространства.
Постараемся всю тематику оптимизации разбить на несколько пунктов, чтоб было более-менее понятно, от чего «котелок» закипает .
Зачем настраивать сервер
В MySQL оптимизацию производительности следует начинать с сервера. Прежде всего, следует ускорить его работу и уменьшить время обработки запросов. Универсальным средством для достижения всех перечисленных целей является включения кэширования. Не знаете, «what is it»? Сейчас все поясню.
Если на вашем экземпляре сервера включено кэширование, то система MySQL автоматически «запоминает» введенный пользователем запрос. И в следующий раз при его повторении данный результат запроса (на выборку) будет не обработан, а взят из памяти системы. Получается, что таким образом сервер «экономит» время на выдачу ответа, и вследствие чего скорость реагирования сайта повышается. В том числе это касается и общей скорости загрузки.
В MySQL оптимизация запросов применима к тем движкам и CMS, которые работают на основе данной СУБД и PHP. При этом код, написанный на языке программирования, для генерации динамической веб-страницы запрашивает некоторые ее структурные части и содержимое (записи, архивы и другие таксономии) из БД.
Благодаря включенному кэшированию в MySQL выполнение запросов к серверу СУБД происходит намного быстрее. За счет чего и повышается скорость загрузки всего ресурса в целом. А это положительно отражается и на пользовательском опыте, и на позиции сайта в выдаче.
Включаем и настраиваем кэширование
Но давайте вернемся от «скучной» теории к интересной практике. Дальнейшую оптимизацию базы MySQL продолжим с проверки состояния кэширования на вашем сервере БД. Для этого с помощью специального запроса мы выведем значения всех системных переменных:
Совсем другое дело.
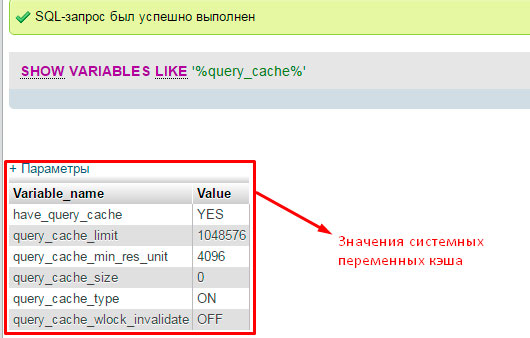
Сделаем маленький обзор полученных значений, которые пригодятся нам для оптимизации баз данных MySQL:
have_query_cache – значение показывает «ВКЛ» кэширование запросов или нет.
query_cache_type – отображает активный тип кэша. Нам нужно значение «ON». Это говорит о том, что кэширование включено для всех видов выборки (команда SELECT). Кроме тех, в которых используется параметр SQL_NO_CACHE (запрещает сохранение информации об этом запросе).
У нас все настройки заданы правильно.
Отмеряем кэш под индексы и ключи
Теперь нужно проверить, сколько отведено оперативной памяти под индексы и ключи. Рекомендуется устанавливать этот важный для оптимизации БД MySQL параметр на 20-30% от объема оперативки, доступной для сервера. Например, если под экземпляр СУБД выделено 4 «гектара», то смело ставьте 32 «метра». Но все зависит от особенностей определенной базы и ее структуры (типов) таблиц.
Для установки значения параметра нужно отредактировать содержимое конфигурационного файла my.ini, который в Денвере находится по следующему пути: F:\Webserver\usr\local\mysql-5.5

Файл открываем с помощью Блокнота. Затем находим в нем параметр key_buffer_size и устанавливаем оптимальный для вашей системы ПК (в зависимости от «гектаров» оперативки) размер. После этого нужно перезапустить сервер БД.

В СУБД используется несколько дополнительных подсистем (нижнего уровня), и все основные их настройки также задаются в данном файле конфигурации. Поэтому, если нужно провести в MySQL InnoDB оптимизацию, то добро пожаловать сюда. Более подробно эту тему мы изучим в одном из наших следующих материалов.
Измеряем уровень индексов
Использование индексов в таблицах значительно повышает скорость обработки и формирования ответа СУБД на введенный запрос. MySQL постоянно «измеряет» уровень применения индексов и ключей в каждой БД. Для получения данного значения используйте запрос:
SHOW STATUS LIKE "handler_read%"
SHOW STATUS LIKE "handler_read%" |

В полученном результате нас интересует значение в строке Handler_read_key. Если указанное там число маленькое, то это говорит о том, что индексы почти не используются в данной базе. А это плохо (как у нас ).
-
 17 апреля 2015Ламповый звук - мифы и факты
17 апреля 2015Ламповый звук - мифы и факты -
 17 апреля 2015Браузер Амиго – полное удаление с компьютера
17 апреля 2015Браузер Амиго – полное удаление с компьютера -
 17 апреля 2015Установка драйвера 1с
17 апреля 2015Установка драйвера 1с






